6 Important Speech Recognition Technology You Should Know
An excellent voice interaction system requires not only a good understanding of natural language, but also a strategy to help users understand the myriad of actions and commands in a voice interaction.
To better understand the voice interaction and apply it into future projects, we have to understand the technical knowledge behind it and how it shapes the users experience.
6 things must know before start a speech recognition application
1. How to recognize a conversation start?
“Hey Siri!”
How does Apple’s Siri recognize the calls to her from other noise and speech?
Keyword Search/Keyword Spotting (KWS) is the basic technology to wake up a smart device. The device recognizes whether there is a certain keyword (wake word), such as “Hey Siri”, in “effective voice” to determine whether the user is sending a command to the device and that it will need to respond.
2. How to recognize the end of a conversation?
Voice Activity Detection (VAD)
With VAD, we can find valid speech segments, eliminate silent segments, and greatly reduce the amount of data to be processed during speech recognition. There is a variety of methods using VAD, such as frame amplitude, and complex neural networks. Most assistants will wait for a set time before assume a command has been issues, then begin to try and understand the the command or request.

3. How to Interrupt a conversation- Acoustic Echo Cancellation (AEC)
What is Acoustic Echo?

The above picture shows that voice (or any other audio) can be transmitted, from a speaker, back to the microphone. This can be direct, or from reflections in the room. Acoustic Echo Cancellation is designed to eliminate this input echo before it passes back into the system. This is how devices can hear you even when they are playing audio.
4. How to hear clearly in a noisy environment?
Noise Suppression (NS) and Beam-forming (BF) help solve this problem.
It is difficult to construct an acoustic model in different environments with various noise. For example, vocals, footsteps and laughter all come up together as noise. However, if someone is calling our name, people can react quickly, but this can be very difficult for a machine.
Noise suppression technology reduces static and transient noise in monophonic speech signals. With Noise Suppression technology, signal-to-noise ratio and speech intelligibility can be improved and listening fatigue will be reduced.
Beam-forming based approach weighs the collected signals by multiple microphones to form a pickup beam in the direction of the target signal, meanwhile the reflected sound from other directions is attenuated. There are many algorithms and approaches to this, but essentially by using multiple microphones you can focus on audio input coming from a specific area.
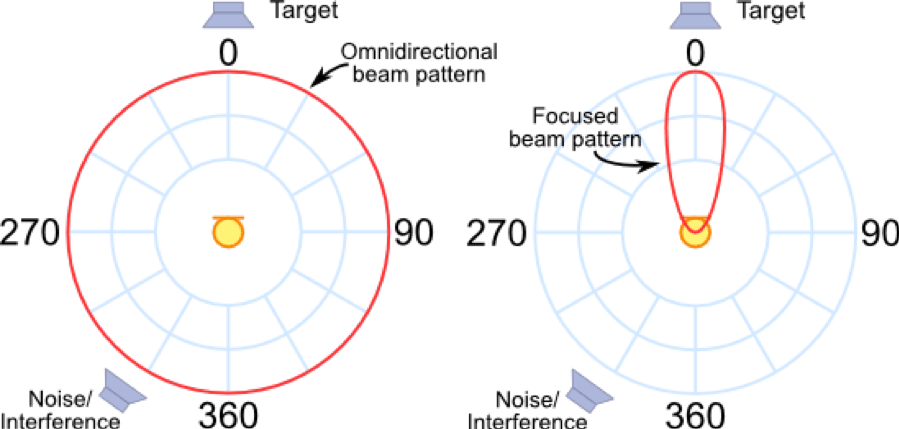
5. Natural Language Understanding
NUI (Natural User Interface) will be applied to many different interaction scenarios. In a conversation interaction, machines need to complete a closed loop of “hear-understand-answer”. This closed loop involves three types of technologies: speech recognition (ASR), natural language processing (NLP), and speech synthesis, also known as text-to-speech (TTS). The most important part of the loop is the NLP, because it decides whether a machine can correctly understand the request and take an appropriate response.
6. How to convert speech to text for NLP, and then a generated text response to speech?
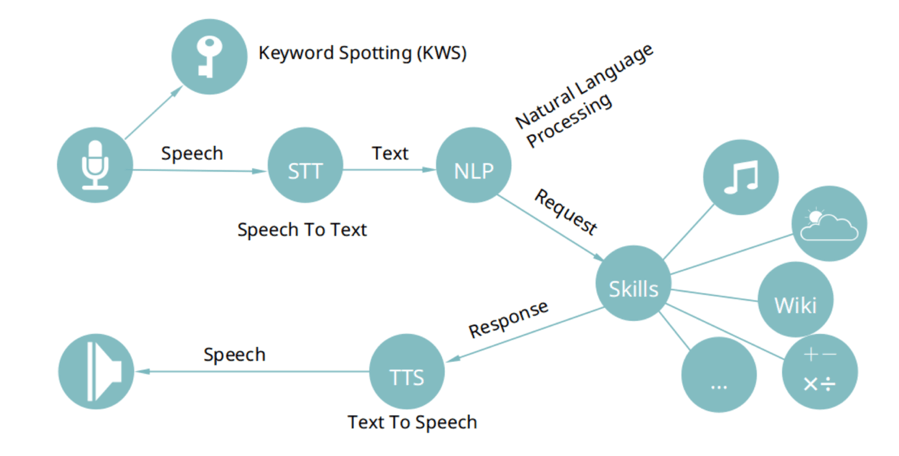
Speech recognition is to transform the words spoken by the user from sound form to text form (speech-to-text, or STT). Natural language processing is to understand the meaning (semantics) to be expressed by these words. The request or command, now understood, will be processed and a text response generated. Finally, the machine will give this corresponding answer in the form of voice, which requires speech synthesis (TTS).
ASR is aiming at converting sound information into text (Speech To Text (STT)). Also,
After the voice assistant starts, it will always listen via the microphone and perform keyword search/keyword spotting (KWS) on the sound content. When it matches the set keyword (that is, the set wake-up word, such as “Siri and “Alexa”), the corresponding operation will be triggered automatically. This is typically ran on the device and does not require information to be sent off device to the internet. This is why you are able to call your voice assistant even without internet connection.
Now that you have an idea of the technology used it’s time to get started on creating a voice interaction project. To do this we have created our ReSpeaker product line.
KWS + STT + NLP + TTS = ReSpeaker
ReSpeaker is an open modular voice interface to hack things around you. It can let you interact with your home appliances, plant, your office, internet-equipped devices or any other things in your daily life, all by your voice. The ReSpeaker project provides hardware components and software libraries to build voice enabled device.

Currently there are three primary board categories for ReSpeaker family. All of these categories are designed to help enable voice interface with different platforms.
- SBC Solution
- Mic Array Solution
- Raspberry Pi Mic Array Solutions
Check our ReSpeaker product guide to choose the best one for your voice interaction project.
For the full document, don’t miss our GitHub! Start your voice enabled project with full tutorials and documents! Welcome to the voice enabled era!
By the way, apply Promo Code: 【BLACKFRIDAY】for all ReSpeaker get 20% OFF during Black Friday!
Need project inspired? Explore at out Project Hub, grow your ideas with Seeekers!
Reference
Rudy BARAGLIA 20th Jun Voice Activity Detection for Voice User Interface.
Jason Kincaid 13rd Jul A Brief History of ASR: Automatic Speech Recognition
Yundong Zhang, Naveen Suda, Liangzhen Lai, Vikas Chandra Hello Edge: Keyword Spotting on Microcontrollers 14th Feb 2018
A comparative study of noise reduction techniques for automatic speech recognition systems
Noise Suppression (NS) technology
Make Google Home hear you in cocktail parties 16th March 2018
Kathryn Whitenton 10th Sep 2017 Audio Signifiers for Voice Interaction