AI Model Development and Deployment on the Edge: All in One-Jetson
In the rapidly developing field of Machine Learning, training AI models is a familiar yet challenging and complex section. Traditionally, this task has been shouldered by robust cloud servers, using their computational capability to update model parameters with extensive datasets. However, the narrative is shifting, thanks to the groundbreaking progress made in Edge AI development and distributed computing.
In this blog, we’ll take a closer look at how traditional AI development and deployment workflow is realized, explore the benefits of completing this whole workflow on the edge, and check out the step-by-step guidance to move forward in your AI application.
AI Application Development Cycle
In the conventional approach, the AI application journey starts with acquiring and organizing data, as the foundation for training robust models. This dataset is labeled carefully, creating a diverse information set that accelerates the model’s learning. After data preparation, model training takes place on powerful computing servers, iterating through the dataset to optimize parameters. The finely-tuned model is then optimized for seamless execution on specific devices, crucial for peak performance. Finally, the model is deployed to Jetson devices over the cloud, ready for real-world AI applications.
Since the AI model performance is highly dependent on the input of real-world data in the ever-changing reality of the scenes, such as intersections, parking lots, retail, QSR, waste recycling, robotics, etc, issues would come up with concerns of latency, bandwidth, and privacy. This may cause difficulty while processing in a centralized cloud or enterprise data center.
But, what if we consider completing the whole process on the edge?
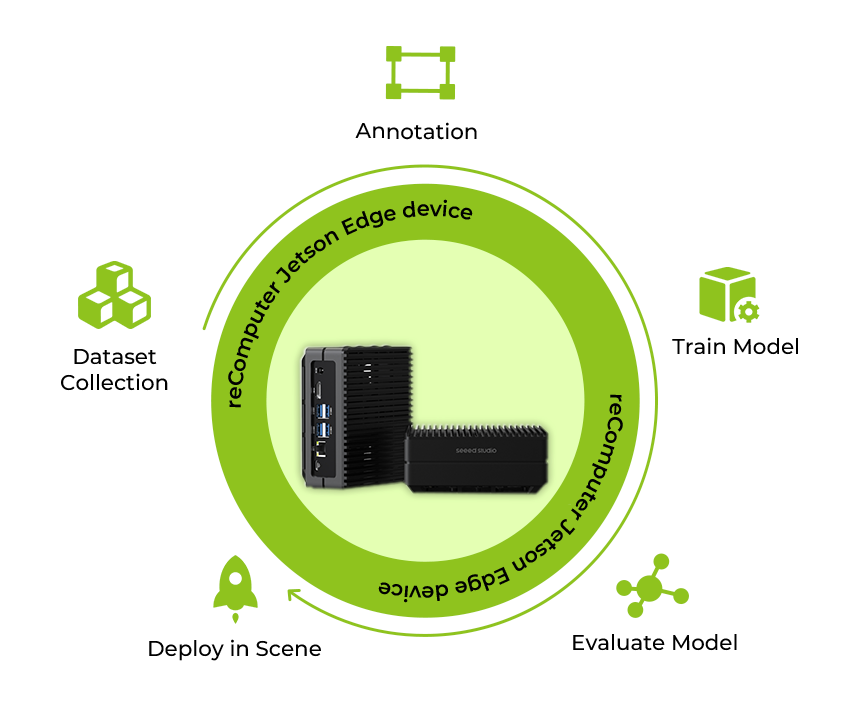
Why Both Train and Deploy Models on the Edge?
1. On-Device Training:
Jetson devices, equipped with sufficient computational power, allow developers to perform on-device training. This means that the AI model can be updated and re-trained directly on the edge device based on the continuous new data input from the real scene, without the need to send data back to a central server or cloud for training, which enables a decentralized and efficient workflow.
2. Enhance Privacy
Jetson enhances privacy by processing data locally and uploading only analyzed insights to the cloud. Even when a subset of data is transmitted for training, robust anonymization safeguards user identities. This not only preserves privacy but also streamlines compliance with data regulations.
3. More Stable Operation
Rather than dealing with fluctuating workloads and potential bottlenecks on traditional computing servers, the Jetson’s efficiency can be shown through its ability to execute operations with precision and stability, running 7×24 without frequent human maintenance and complex overhaul.
4. Minimize Latency
The Jetson Edge device stands out as a latency-reducing powerhouse due to its streamlined data processing approach. It eliminates the need for data to traverse back and forth between the deployment end and a central server, a critical factor for achieving real-time response in applications. By focusing on transmitting concise, updated data rather than the complete large datasets, the Jetson optimizes bandwidth efficiency. It delivers only the essential information needed for quick decision-making, building the Jetson a formidable solution for applications demanding swift and responsive computing.
Complete the Entire Procedure on Jetson Orin NX
Now, I’m glad to lead you to train and deploy an object detection model referring to the YOLOv8 object detection algorithm for the busy traffic road, where we use reComputer J4012 Jetson Orin NX 16GB with pre-installed Jetpack 5.1.1 version. Appreciate the contribution of our application engineer Youjiang to build this demo and figure out the clear path, feel free to also check out the full details in this wiki.
Dataset Collection
We have two methods to prepare a high-quality dataset for good model performance:
1. Download the pre-annotated open-source public dataset
You can find a proper public dataset fitting for your application scenario through open platforms such as Roboflow, Kaggle, and so on. After downloading the traffic Detection project dataset from Kaggle, you need to modify the paths that direct to locations of training, testing, and validating sets in the data.json file.
train: ./train/images
val: ./valid/images
test: ./test/images
nc: 5
names: ['bicycle', 'bus', 'car', 'motorbike', 'person']2. Collect and label images as your dataset for training
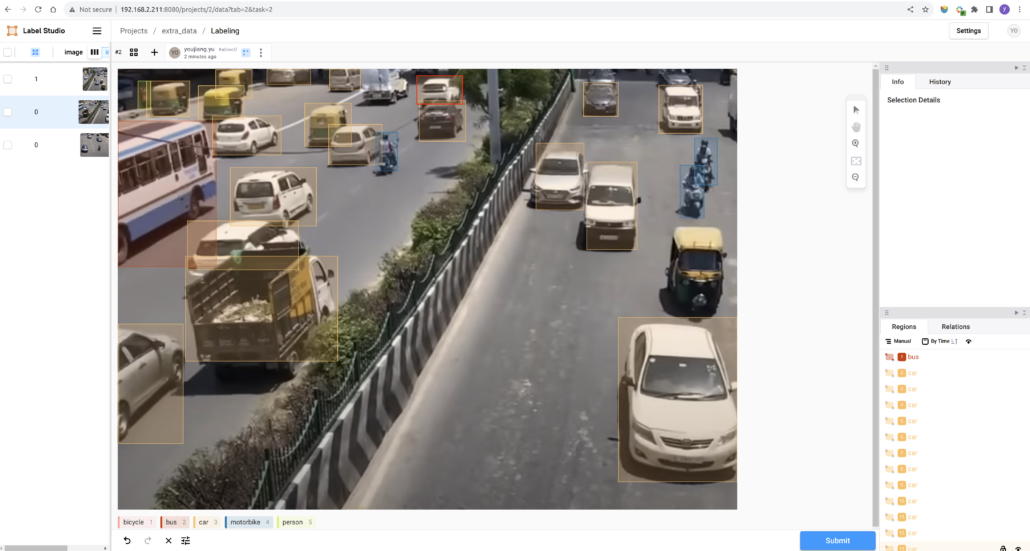
Easily get started annotating images with Label Studio. before doing that, install and run the annotation tool as follows:
sudo groupadd docker
sudo gpasswd -a ${USER} docker
sudo systemctl restart docker
sudo chmod a+rw /var/run/docker.sock
mkdir label_studio_data
sudo chmod -R 776 label_studio_data
docker run -it -p 8080:8080 -v $(pwd)/label_studio_data:/label-studio/data heartexlabs/label-studio:latestFollow the step guides to create your annotation project, and export the dataset in YOLO format. To organize them with the downloaded data together, you can save all images to the train/images folder, and then copy the generated annotation text files to the train/labels folder, both two folders are for the public dataset.
Set up Runtime Environment
Here we are going to download the YOLOv8 source code on reComputer, modify the requirements.txt first, and install the PyTorch Jetson version. Follow the wiki commands.
Remember to check if you have already installed YOLO successfully:
yolo detect predict model=yolov8s.pt source='https://ultralytics.com/images/bus.jpg'Train Your Model
Revise your Python script by editing as follows, it’s optional to use the CLI approach to train the model by setting up different configurations based on your specific scenario requirements. The full steps for the training part can be found in the wiki.
from ultralytics import YOLO
# Load a model
model = YOLO('yolov8s.pt')
# Train the model
results = model.train(
data='/home/nvidia/Everything_Happens_Locally/Dataset/data.yaml',
batch=8, epochs=100, imgsz=640, save_period=5
)After the training progress finishes, you’ll see the model weight files saved in the specific folder:

Model Validation & Deployment
By verifying the prediction results, you’ll first figure out if the model can perform the expected capability in the real scenario. However, it’s just the verification of the model feasibility, without considering the inferencing speed based on the practical requirements in the real-world application. So, finding the balance between efficiency and prediction accuracy plays a crucial role during the deployment process. TensorRT Inference engine can help improve the inferencing speed of the model. Follow the wiki to generate the inference.py file and replace the model and cap part with your paths.
To make a more versatile model with faster inference, the quantized model is also important to take into the deployment part. based on our test in this demo, the inferencing performance could be leveraged from 21.9 FPS to 29.76 FPS after using the quantized model.

Looking ahead, it’s still crucial to focus on advancing inferencing speed. Leveraging the exceptional Orin NX AI performance, reaching up to 100 TOPS, the next step involves fine-tuning the AI model to unlock even greater speeds in edge AI inferencing.
It’s also achievable to accelerate the AI development process by synergizing generative AI with the entire loop, which can not only enhance model generative capability by fast dataset extension but also re-train AI models with the transfer learning ability based on a smaller amount of task-specific data. All these advancements could be handled with our reComputer Jetson Orin edge device, and then further seamlessly integrated into end-to-end edge AI application development and deployment pipelines, continuing to show innovation in diverse industry fields and ecosystems.
Join the forefront of AI innovation with us! Harness the power of cutting-edge hardware and technology to revolutionize the deployment of machine learning in the real world across industries. Be a part of our mission to provide developers and enterprises with the best ML solutions available. Check out our success case study catalog to discover more edge AI possibilities!
Discover infinite computer vision application possibilities through our vision AI resource hub!
Take the first step and send us an email at [email protected] to become a part of this exciting journey!
Download our latest Jetson product Catalog to find one option that suits you well. If you can’t find the off-the-shelf Jetson hardware solution for your needs, please check out our customization services, and submit a new product inquiry to us at [email protected] for evaluation.