NVIDIA Jetson Nano and Jetson Xavier NX Comparison: Specifications, Benchmarking, Container Demos, and Custom Model Inference

New release for NVIDIA Jetson Nano and Jetson Xavier NX
reComputer Jetson series are compact edge computers built with NVIDIA advanced AI embedded systems:
- reComputer J1010, J1020 (built with Jetson Nano Module 4GB)
- reComputer J2011, J2012 (built with Jetson Xavier NX Module 16GB/8GB).
With rich extension modules, industrial peripherals, thermal management, reComputer is ready to help you accelerate and scale the next-gen AI product by deploying popular DNN models and ML frameworks to the edge and inferencing with high performance, for tasks like real-time classification and object detection, pose estimation, semantic segmentation, and natural language processing (NLP).
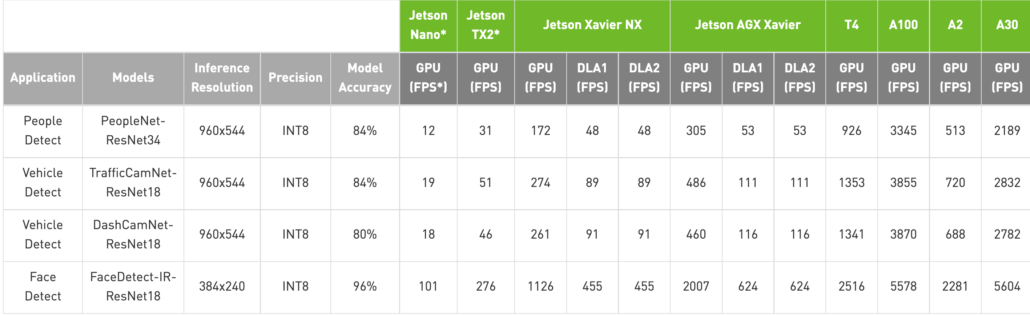
With Jetson Nano, developers can use highly accurate pre-trained models from TAO Toolkit and deploy with DeepStream. Jetson Nano can achieve 11 FPS for PeopleNet- ResNet34 of People Detection, 19 FPS for DashCamNet-ResNet18 of Vehicle Detection, and 101 FPS for FaceDetect-IR-ResNet18 of Face Detection. Benchmark details can be found on NVIDIA®’s DeepStream SDK website.
With Jetson Xavier NX, developers can use highly accurate pre-trained models from TAO Toolkit and deploy with DeepStream. Jetson Xavier NX can achieve 172 FPS for PeopleNet- ResNet34 of People Detection, 274 FPS for DashCamNet-ResNet18 of Vehicle Detection, and 1126 FPS for FaceDetect-IR-ResNet18 of Face Detection. Benchmark details can be found on NVIDIA®’s DeepStream SDK website.
The following article is a transcript from the video published on Hardware.ai YouTube channel. It also appeared on Hackster.io
Don’t miss out on NVIDIA Jetson Xavier NX and NVIDIA Jetson Nano at Seeed!
Today we’re going to have a good look at a new development kit from NVIDIA – Xavier NX and compare it to another dev kit from NVIDIA, Jetson Nano. The compute module Xavier NX was announced on November 6, 2019, but the development kit, which includes the module and reference carrier board was announced just half a year later, on May 14, 2020. This is the opposite situation of what happened with Nvidia Jetson Nano – in that case, development kit came first and then the compute module became available for purchase.
So, how does Xavier NX compare to Jetson Nano? The price difference is significant, 99 USD vs. 399 USD or about 400 percent. Is there a clear threshold for when you know that Jetson Nano is not enough for your application and you need to up your game a level?

Before we start our comparison, we should note that these two products being targeted for different target groups – Nvidia Jetson Nano is for makers and STEM education, while Xavier NX is more geared towards professional and commercial use. It was very obvious from the sample applications that Nvidia released on product’s launch – for Jetson Nano it was Jetboat with a series of user-friendly notebooks and for Jetson Xavier NX it was a demo of cloud-native applications, which appeals to commercial users. That still warrants a comparison to be made – think about it as Xavier NX being a sports car with two turbo engines and Jetson Nano is a more down to earth sedan. We don’t always go for the fastest car available, even if we have the money, there are many other considerations to take.
In this article, we’ll go over
- Hardware Overview
- Specs
- Benchmarking
- Cloud-Native container demo
Custom Model Inference
Let’s look into these small but quite important details sometimes overlooked in other reviews.
Hardware and Specification Comparison of NVIDIA Jetson Nano and Jetson Xavier NX
Let’s start by looking at two dev kits side by side. I’ll skip the unpacking, because, well, you know how to open a box without me. If not, please leave a comment below, I’ll make another tutorial soon. Fist, the similarities. Both dev boards are similar in size and the modules are exactly the same size and form factor. Which is great for developers, it means that during developments stage swapping Nano module for Xavier NX won’t require changing connectors and physical design of carrier board (providing they use Rev B01 of Jetson Nano Dev Kit).

Both carrier boards have Gigabit Ethernet Jack, 4 USB 3 ports (although for Xavier NX it is USB 3.1 and for Jetson Nano it is 3.0), HDMI port and display ports.
Now the differences. Xavier NX dev kit board has one M2 Key E and one M2 Key M connector, with M2 Key E slot already occupied with BT/WiFi module. M2 Key M can be used for attaching NVME SSD. Jetson Nano carrier board only has one M2 Key E connector. The Jetson Nano carrier board I have here is A02 carrier board, the one that originally went on sale when Jetson Nano dev kit was just released – it has some differences from B01 Carrier Board, notably B01 has two CSI-2 camera interface, same as Xavier NX carrier board, while A02 you see here just has one.

Xavier NX has an active cooling installed, while Jetson Nano only has a heatsink. It’s because Xavier is much more power-hungry than it’s a younger cousin – the dev kit cannot be powered by 5V USB and requires 19V power supply, which fortunately is included in the box. The reference carrier board of Xavier NX has more well-thought design with a little plastic base, that serves two purposes: protects the circuits from directly touching the surface of your workplace and holds two antennas. A slight detail, but very nice.
You can also check our blog New Revision of Jetson Nano Dev Kit – Now supports the new Jetson Nano Module to have a detailed look at how the new B01 revised carrier board id different from the A02 board.
Specs
Let’s quickly compare the specs now, using the data from official NVIDIA website.
Apart from very obvious things, such as Xavier NX having CPU with more cores and higher clock rate and more RAM(faster too, 25.6GB/s vs 51.2GB/s), it is the AI Performance column that worth paying more attention too. Before you go, “Holy cow, the AI performance of Xavier NX is 44 times higher, than of Jetson Nano”(21/0.472~44) it is worth noting that the comparison is between different units TOPS vs TFLOPS.
_srvfMlxeHL.jpg?auto=compress%2Cformat&w=740&h=555&fit=max)
The reason for that is for Xavier NX, the compute of NVDLA Engines is included in that very impressive number. Jetson Nano (and older members of Jetson family, TX1/TX2) only have GPU for accelerating ML inference, which is optimized for floating-point operations. NVDLA Engines on the other hand are different beasts entirely and are ASICs or Application Specific Integrated Circuits, more akin to Google TPU/Intel Movidius chips.
_ID1TWadLOc.jpg?auto=compress%2Cformat&w=740&h=555&fit=max)
They excel at running CNN inference in INT8 precision, doing that task faster and more energy efficient than GPUs – the downside being that they are not as the general purpose when it comes to different network architecture support. NVIDIA realized that GPUs alone cannot beat highly specialized hardware and decided to take the best of both worlds by having both advanced 384-core NVIDIA Volta™ GPU with 48 Tensor Cores and dedicated CNN accelerators in the new module.
_D6lMaiHXq3.jpg?auto=compress%2Cformat&w=740&h=555&fit=max)
Speaking of Tensor Cores, we also see that these are missing from Nvidia Jetson Nano’s GPU. Now, what on Earth is Tensor core? That’s exactly the title of an article on the first page of Google Search results for tensor core. Comparing to CUDA cores, CUDA cores operate on a per-calculation basis, each individual CUDA core can perform one precise calculation per revolution of the GPU. As a result, clock speed plays a major role in the performance of CUDA, as well as the mass of CUDA cores available on the card. Tensor cores, on the other hand, can calculate with an entire 4×4 matrice operation being calculated per clock.
Look at the animation here to get a sort of intuitive understanding of what is going on in regular CUDA core and Tensor core.
Benchmarking
Alright, that was a brisk, but invigorating walk through forests of high-performance computing. If you’re an engineer like me, you want to know how exactly all of that translates to inference performance. This time NVIDIA created a dedicated repository with easily downloadable and executable benchmarks, a decision I can applaud to. So, I ran the benchmarks from this repository on both Nvidia Jetson Nano and Xavier NX. Quite unsurprisingly the results were very close to these from Nvidia Blog article.

Something worth paying attention to is that for Xavier NX the total FPS is the sum of FPS obtained from running model on two DLA and GPU simultaneously. You can find that by looking at the content of benchmark.py.
# Note: GPU, DLA latencies are measured in miliseconds, FPS = Frames per Secondprint(benchmark_table[['Model Name', 'DLA0 (ms)', 'DLA1 (ms)', 'FPS']])You can modify it to print out the total FPS and inference time for each device (for Xavier NX), like that.
Container demo
The second test will be using much touted new features in Jetpack 4.4, “cloud-native”. Basically, it is about bringing containerization, and orchestration from servers to edge devices. Why do that? To simplify the continued development. Containers are self-contained packages, that include all the necessary environment to run an application. The main selling point of containerization is that they make upgrades easier – because they’re self-contained, you don’t need to worry about updating one package will cause versioning bugs in your whole system. Nvidia prepared a “customer service” robot demo to showcase the new container management system and hardware capabilities of Xavier NX. Unfortunately, because 3 of 4 containers for that demo have TensorRT engine files built for Jetson AGX Xavier and Jetson Xavier NX and can be run on Jetson AGX Xavier or Jetson Xavier NX only. So, we’ll download and try another container, Deepstream-L4T, and run sample application from within the container. Sample application are already precompiled and ready to run within containers. Unfortunately, they hard-coded to look for their respective config file in the folder where you run the application, which might cause some confusion.
Download the container with
sudo docker pull nvcr.io/nvidia/deepstream-l4t:5.0-dp-20.04-samplesAllow external applications to connect to the host’s X display
xhost +After that run the container with
sudo docker run -it --rm --net=host --runtime nvidia -e DISPLAY=$DISPLAY -w /opt/nvidia/deepstream/deepstream-5.0 -v /tmp/.X11-unix/:/tmp/.X11-unix nvcr.io/nvidia/deepstream-l4t:5.0-dp-20.04-samplesThen move to the folder with app config file
cd sources/apps/sample_apps/deepstream-test3And execute the test app – copy and paste the file name to run on multiple streams:
deepstream-test3-app file:///opt/nvidia/deepstream/deepstream-5.0/samples/streams/sample_720p.mp4we will go for deepstream-apptest3 and run it with 720p video. Jetson Nano can only run smoothly one video stream, once we add the second one, performance drops significantly. For Jetson Xavier we see a similar picture, once we add the second stream, it starts dropping frames.
_eWxGqkd1su.jpg?auto=compress%2Cformat&w=740&h=555&fit=max)
Upon checking with jetson_stats we see that CPU and GPU load never reaches 100 percent, so possibly the performance bottleneck here is in SD card reading speed. For their “service robot” demo application that runs 4 containers simultaneously it is necessary to use NVME SSD.
Custom model inference
As for our final comparison, let’s try stepping aside from the demos Nvidia have provided and using a model we trained ourselves. In the end, this is the real test of performance and user-friendliness – the results you can achieve, as opposed to carefully optimized demos. We will use aXeleRate, a Keras-based framework for AI on the edge. Its purpose is to simplify the training and conversion of models to be run on various edge devices, such as K210, Edge TPU, Android/Raspberry Pi, and Nvidia dev boards. NVIDIA’s model optimization toolkit, TensorRT is very different from other toolkits for model conversion, such as nncase, Google Coral converter. Unlike the rest of them, with TensorRT you need to optimize model on the target device, since optimizations depend on the target device’s architecture. TensorRT definitely deserves a video – possibly a video series of its own, and I will make one in near future.
We will use NASNetMobile trained on Stanford dog breeds dataset – go through the steps in the notebook, remember to modify the config file to enable the conversion to.onnx format!

After training is done download the.onnx file to Jetson and run onnx_to_trt.py file in the example_scripts/nvidia_jetson/classifier folder.
onnx_to_trt.py -- onnx (path to .onnx file) --precision FP32The script will convert.onnx model to serialized.plan file which has a model graph optimized for target device – meaning that you will not be able to run.plan file created on Xavier NX on Jetson Nano and vice-versa.
Now we can run classifier_video.py on a sample video file.
classifier_video.py --model (path to .plan file) --labels (path to .txt file with labels) --source (path to video file)You can use
classifier_video.py --model (path to .plan file) --labels (path to .txt file with labels) --source 0to run real-time inference from USB web camera.
Jetson Nano averages FPS around 15 frames per second and Jetson Xavier can process the video with adorable dogs at ~30 frames per second.
_Zf3vJlllYI.jpg?auto=compress%2Cformat&w=740&h=555&fit=max)
Conclusion
In conclusion, new Nvidia Jetson Xavier NX is a beast.
It’s power-hungry, but if performance is what you’re aiming for then it is the best module you can get at this footprint and price. If you are developing an application that requires processioning multiple video streams at high resolution while performing ASR/NLP or another GPU related tasks (CUDA enabled SLAM for example), then it’s deep learning accelerators can take on CNN inference and leave GPU for other tasks – something that older TX2 or Jetson Nano are not capable of. For makers and hobbyists – well, if you’re buying it, make sure you already thought of an application that requires that much horsepower under the trunk, and also you have enough technical knowledge to eliminate any performance bottlenecks if these are present.