What is FastSAM: How to Segment Anything on the Edge?
FastSAM was born to tackle the issue of the substantial computational resource requirements associated with heavy Transformer(ViT) models. By harnessing the power of the lightweight CNN model, FastSAM becomes a more effective method rather than SAM, capable of segmenting any object in an image under the guidance of user interactive prompts, all in real-time and much faster!
Introducing SAM and Beyond
Compared with traditional dataset labeling and collection methods, which require lots of resources and time to retrain the model once the dataset has been changed, SAM stands out as a fully automatic cued image segmentation model that can cut out almost anything from an image. Being trained on 11 million images and 1.1 billion segmentation masks, SAM is capable of generating or retrieving masks for specific objects in an image based on points/text prompts.
FastSAM goes beyond that. It converts the task into an instance segmentation task, using only 1/50 of the SA-1B dataset published by Meta AI, and finally achieves 50 times faster runtimes while achieving comparable accuracy to SAM.

Two Stages for FastSAM
Break down FastSAM into two stages: All-instance Segmentation (AIS) and Prompt-guided Selection (PGS). The first one is the basic method to segment all objects or regions in one image, and the second one is task-oriented post-processing, helping to identify the specific object of interest.
ALL-instance Segmentation
The first stage uses YOLOv8-seg to produce the segmentation masks of all instances in the image.
YOLOv8’s backbone network and neck module substitute YOLOv5’s C3 module with the C2f module. The updated Head module embraces a decoupled structure, separating classification and detection heads, and shifts from Anchor-Based to Anchor-Free.

YOLOv8-seg applies YOLACT principles for instance segmentation. It begins with feature extraction from an image via a backbone network and the Feature Pyramid Network (FPN), integrating diverse-size features. The output consists of the detection and segmentation branches.
Prompt-guided Selection
In the second stage, it outputs the region-of-interest corresponding to the prompt. Here are three methods:

- Point prompts:
- Employ foreground/background points as the prompt
- To avoid errors that one foreground point could be located in multiple masks, background points can be utilized to identify masks that are relevant to the task
- Merge multiple masks within the region of interest into a single mask, in order to completely mark the object of interest
- Box prompts
- Perform Intersection over Union (IoU) matching between the selected box and the bounding boxes to the various masks from the first phase
- Select the object of interest based on the highest IoU score of mask identification
- Text prompts
- Leverage the CLIP model to extract corresponding text embeddings, which represent intrinsic features matched with each mask
- Select the mask with the highest similarity score to the image embeddings of the text prompt
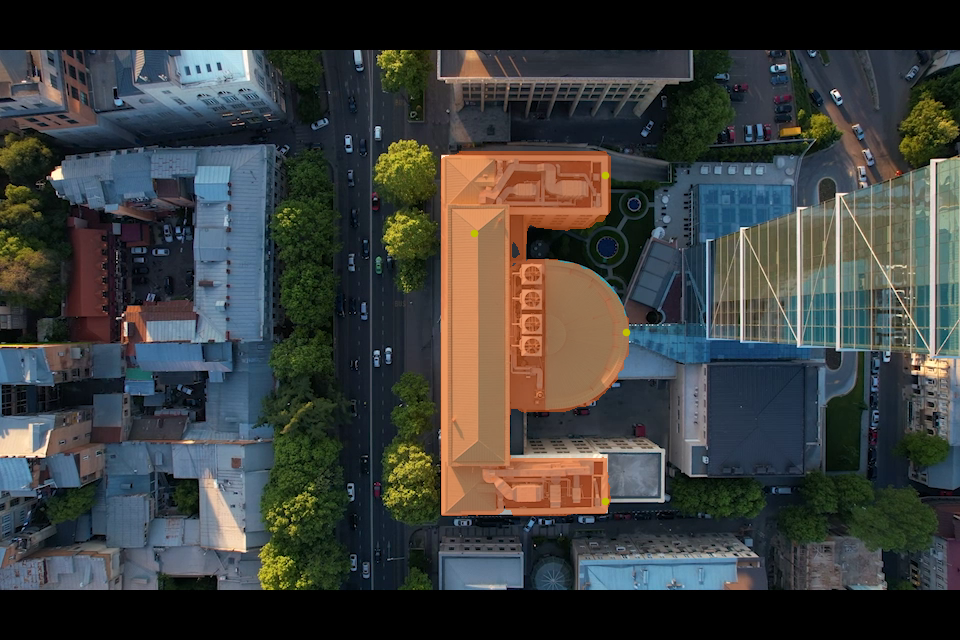
Application Scenarios in Real World
Anomaly Detection
This is normally used to complete sample defect-detecting tasks in a wide range of industrial scenarios, such as manufacturing quality control, predictive maintenance for IoT machines/devices, vital health signs monitoring, and unusual behavior detection in video analytics.
FastSAM can segment the exact defective regions based on foreground/background points/box prompt selection, but it’ll achieve a lower precision rather than SAM under mask everything mode.
Salient object Segmentation
This method aims to identify and isolate the most visually distinct and relevant objects within an image/video, capable of handling multiple visual perception scenarios, including behavior analysis in psychology and eye-tracking studies, interact enhancement in Augmented Reality, important anatomical structures isolation in diagnostics, and bio-feature extraction for security management.
FastSAM shows a similar performance with SAM, with only minor details lost at the edges of the object. Another limitation is that the FastSAM-box prompt can not select multiple objects with a single box, even SAM-box is currently not possible to achieve.
Building Extracting
This will benefit various industries and contribute to the efficient management and development of urban areas and infrastructure. Usually, we see it playing a key role in city planning, navigation system improvement, network coverage optimization, public transportation planning, and land use/crop management.
FastSAM shows great results in identifying one building from the others, but fewer regions related to shadows can be detected compared with SAM. However, while using the FastSAM- point prompt in the region of shadows, it’ll still get the correct result combing with the original building object, which indicated that FastSAM performs great when dealing with resisting the effects of the noise.
How to get started with FastSAM
Check out Ultralytics’ FastSAM docs for integrating the model into your Python application, where you’ll see two options: the official FastSAM Github repo, and Ultralytics Python API to streamline this process.
Tips for you! Here’s a quick tour from our AE Youjiang to show you the FastSAM building extraction demo from the video input with reComputer J4011 powered by NVIDIA Jetson Orin NX:
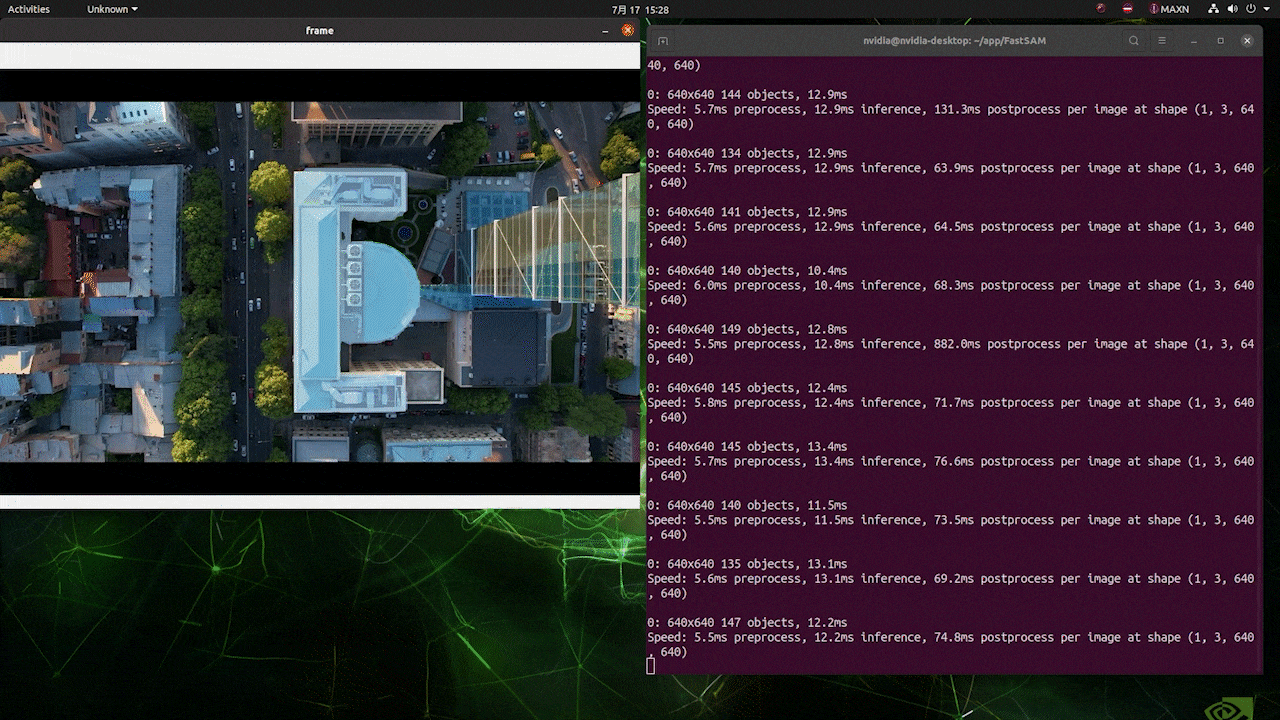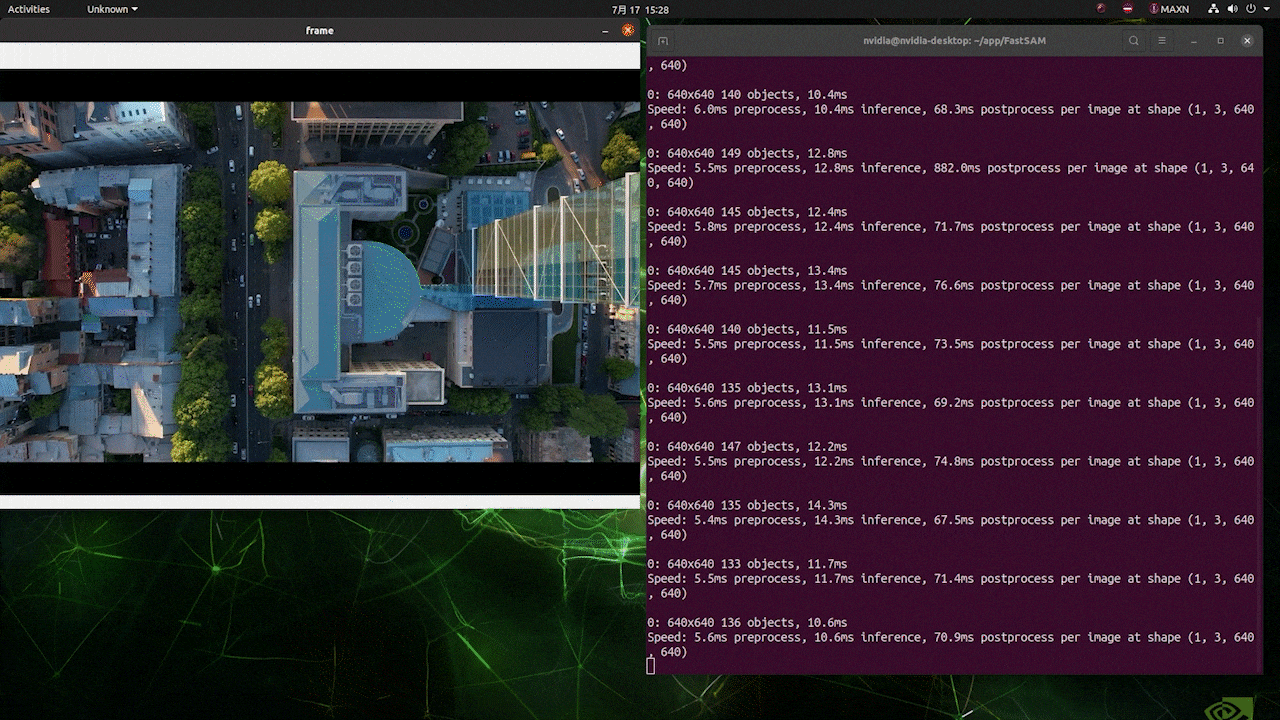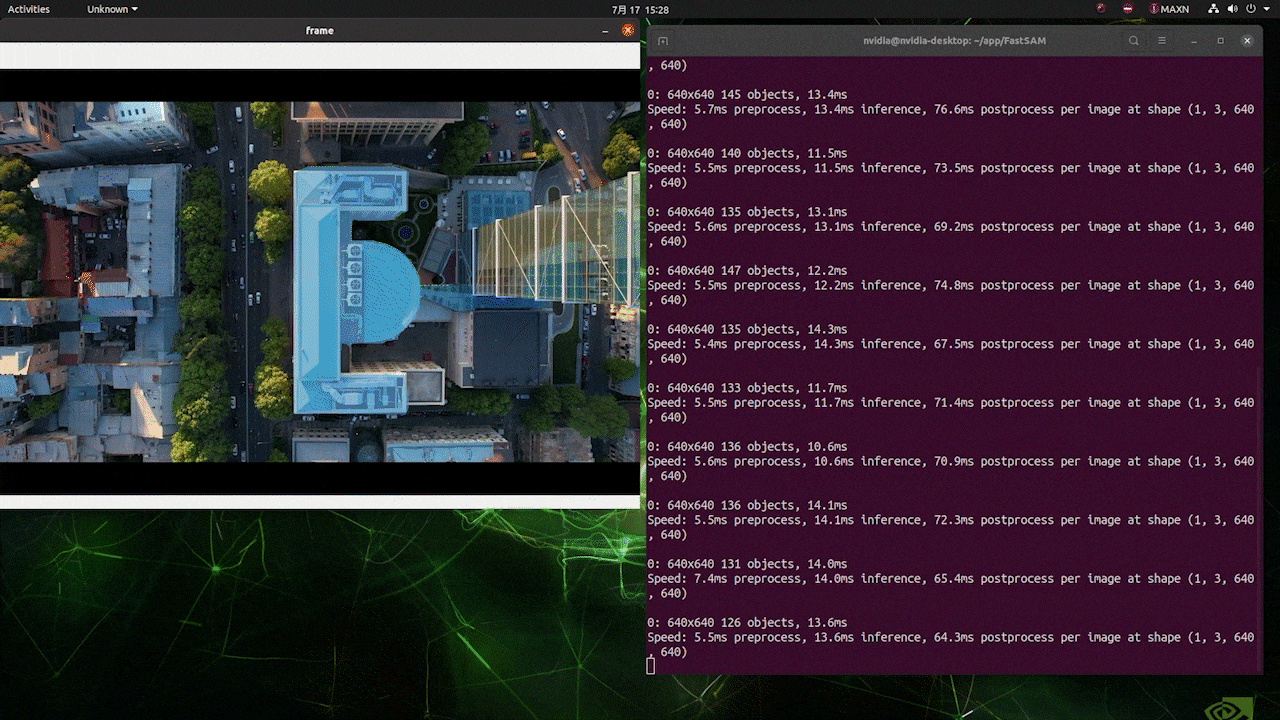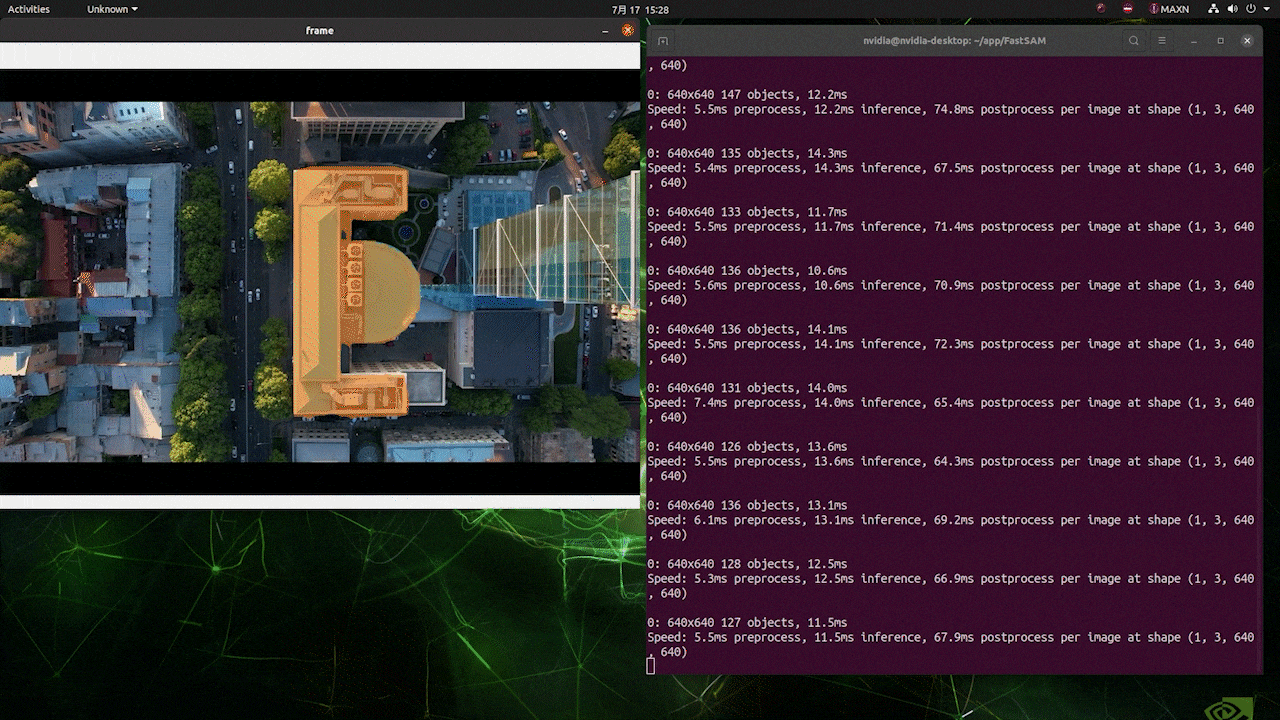
- Install Jetpack OS into reComputer device
- Clone the FastSAM repo and install the CLIP model, PyTorch, and Torchvision
- Clone Youjiang’s repo to get Inference.video.py file, which should be added to the branch of the FastSAM repo next to the original Inference.py
- Use the pre-trained PyTorch model for inferencing on the Jetson device.
- Download model weights in PyTorch format
- Create a new Python script and enter the following code. Save and execute the file
from ultralytics import YOLO
model = YOLO('FastSAM-s.pt') # load a custom trained
# TensorRT FP32 export
# model.export(format='engine', device='0', imgsz=640)
# TensorRT FP16 export
model.export(format='engine', device='0', imgsz=640, half=True)- Then, time to run the demo!
#For Video
python3 Inference_video.py --model_path <path to model> --input_path <path to input video> --imgsz 640#For Webcam
python3 Inference_video.py --model_path <path to model> --input_path <id of camera> --imgsz 640Check out the full steps from Youjiang’s GitHub to try by yourself.
Why reComputer
reComputer J4011 with NVIDIA Jetson Orin NX 8GB module delivers up to 70 TOPS of AI performance to the edge, featuring a rich set of IOs including USB 3.2 ports(4x), HDMI 2.1, M.2 key E for WIFI, M.2 Key M for SSD, RTC, CAN, Raspberry Pi GPIO 40-pin and more. It is also equipped with an aluminum case, a cooling fan with a heatsink, and a pre-installed JetPack 5.1.1 System. Perfect choice to deploy for edge AI solution providers working in video analytics, object detection, natural language processing, medical imaging, and robotics across industries of smart cities, security, industrial automation, and smart factories.

Seeed NVIDIA Jetson Ecosystem
Seeed is an Elite partner for edge AI in the NVIDIA Partner Network. Explore more carrier boards, full system devices, customization services, use cases, and developer tools on Seeed’s NVIDIA Jetson ecosystem page.
- Join the forefront of AI innovation with us! Harness the power of cutting-edge hardware and technology to revolutionize the deployment of machine learning in the real world across industries. Be a part of our mission to provide developers and enterprises with the best ML solutions available.
- Take the first step and send us an email at [email protected] to become a part of this exciting journey! Explore our latest success stories to find the right solution in your industry!
- Download our latest Jetson Catalog to find one option that suits you well. If you can’t find the off-the-shelf Jetson hardware solution for your needs, please check out our customization services, and submit a new product inquiry to us at [email protected] for evaluation.
Reference
- Fast Segment Anything paper, from Xu Zhao, Wenchao Ding, Yongqi An, Yinglong Du, Tao Yu, Min Li, Ming Tang, and Jinqiao Wang: https://arxiv.org/pdf/2306.12156.pdf
- What is Segment Anything Model (SAM)? A Breakdown, from Jacob Solawetz: https://blog.roboflow.com/segment-anything-breakdown/
- Paper Review: Fast Segment Anything, from Andrew Lukyanenko: https://artgor.medium.com/paper-review-fast-segment-anything-912d198557ca