YOLOv8 Performance Benchmarks on NVIDIA Jetson Devices
This blog will talk about the performance benchmarks of all the YOLOv8 models running on different NVIDIA Jetson devices. We have specifically selected 3 different Jetson devices for this test, and they are the Jetson AGX Orin 32GB H01 Kit, reComputer J4012 built with Orin NX 16GB, and reComputer J2021 built with Xavier NX 8GB.
What is YOLOv8?
YOLOv8, developed by Ultralytics, is a cutting-edge, state-of-the-art (SOTA) model that builds upon the success of previous YOLO versions and introduces new features and improvements to further boost performance and flexibility. YOLOv8 is designed to be fast, accurate, and easy to use, making it an excellent choice for a wide range of object detection, image segmentation, and image classification tasks.

YOLOv8 Models Types
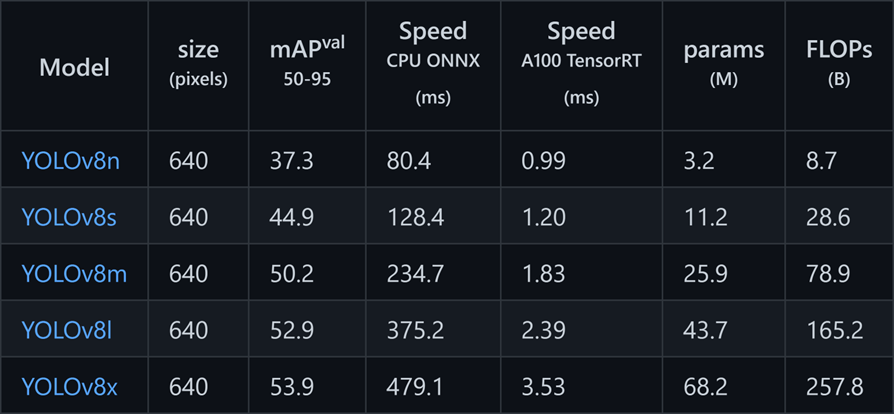
YOLOv8 has different model types based on the number of parameters that will relate to the accuracy of the model. So, the bigger the model, the more accurate it is. For example, YOLOv8x is the biggest model and it has the highest accuracy out of all the models.
Why Do We Need to Benchmark Performance?
By running performance benchmarks, you can know how much of an inference performance you can obtain for a particular model type running on a particular device. This is more important for embedded devices such as the NVIDIA Jetson platform because if you know the exact model type you want to use for your application, you can decide which hardware will be suitable to run that model.
Why Do We Need TensorRT Benchmarks?
TensorRT is a library developed by NVIDIA to make inference faster on NVIDIA GPUs. TensorRT is built on CUDA and it can give more than 2 to 3 times faster inference on many real-time services and embedded applications when compared with running native models such as PyTorch and ONNX without TensorRT.
Install YOLOV8 on Nvidia Jetson Devices
Step 1: Flash the Jetson device with JetPack as explained in this wiki.
Step 2: Follow the sections “Install Necessary Packages” and “Install PyTorch and Torchvision” of the above wiki to install YOLOv8 on the Jetson device
How to Run the Benchmarks?
When you install NVIDIA JetPack with SDK components on an NVIDIA Jetson device, there will be a tool called trtexec. This tool is actually located inside TensorRT which comes with SDK components installation. This is a tool to use TensorRT without having to develop your own application. The trtexec tool has three main purposes
- Benchmarking networks on random or user-provided input data.
- Generating serialized engines from models.
- Generating a serialized timing cache from the builder.
Here we can use trtexec tool to quickly benchmark the models with different parameters. But first of all, you need to have an ONNX model and we can generate this ONNX model by using Ultralytics YOLOv8.
Step 1: Build ONNX model using:
yolo mode=export model=yolov8s.pt format=onnxThis will download the latest yolov8s.pt model and convert to ONNX format
Step 2: Build engine file using trtexec as follows:
cd /usr/src/tensorrt/bin
./trtexec --onnx=<path_to_onnx_file> --saveEngine=<path_to_save_engine_file>For example:
./trtexec --onnx=/home/nvidia/yolov8s.onnx -- saveEngine=/home/nvidia/yolov8s.engineThis will output performance results as follows along with a generated .engine file. By default, it will convert ONNX to an TensorRT-optimized file in FP32 precision and you can see the output as follows
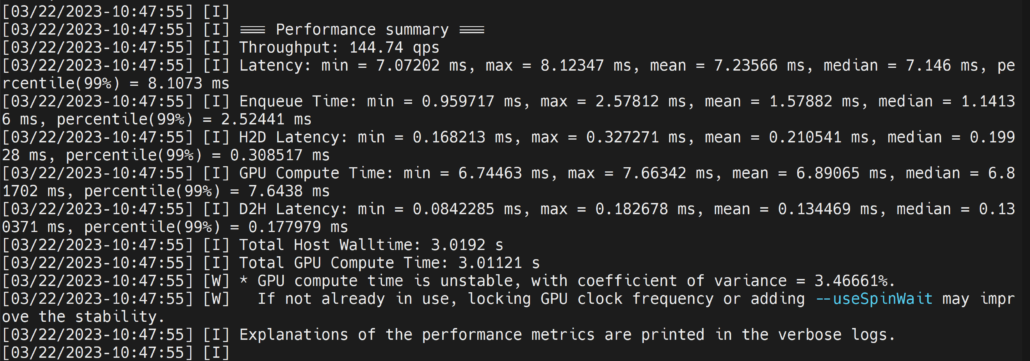
Here we can take the mean latency as 7.2ms which translates to 139FPS.
However, if you want INT8 precision which offers better performance, you can execute the above command as follows
./trtexec --onnx=/home/nvidia/yolov8s.onnx --saveEngine=/home/nvidia/yolov8s.engine --int8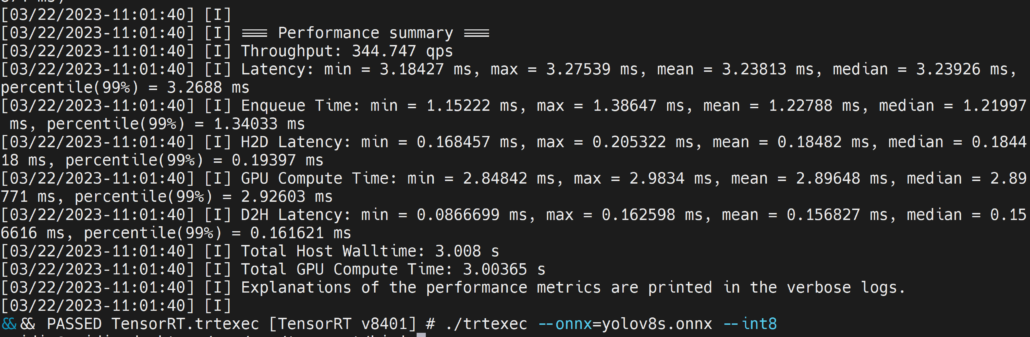
Here we can take the mean latency as 3.2ms which translates to 313FPS.
If you also want to run in FP16 precision, you can execute the command as follows:
./trtexec --onnx=/home/nvidia/yolov8s.onnx --saveEngine=/home/nvidia/yolov8s.engine --fp16To check the performance on the default PyTorch version of the YOLOv8 models, you can simply run inference and check the latency as follows
yolo detect predict model=yolov8s.pt source='<>' Here you can change the source according to the table illustrated on this page.
Also, if you do not specify a source, it will use an image named “bus.jpg” by default.
Benchmark Results
Before moving on to the benchmark results, I will quickly highlight the AI performance of each device we used for the benchmarking process.
| Jetson Device | AGX Orin 32GB H01 Kit | reComputer J4012 built with Orin NX 16GB | reComputer J2021 built with Xavier NX 8GB |
|---|---|---|---|
| AI Performance | 200TOPS | 100TOPS | 21TOPS |
Now we will look at benchmark graphs to compare the YOLOv8 performance on a single device at a time. I have performed all the benchmarks with the default PyTorch model file in 640×640, converted into ONNX format as explained above.
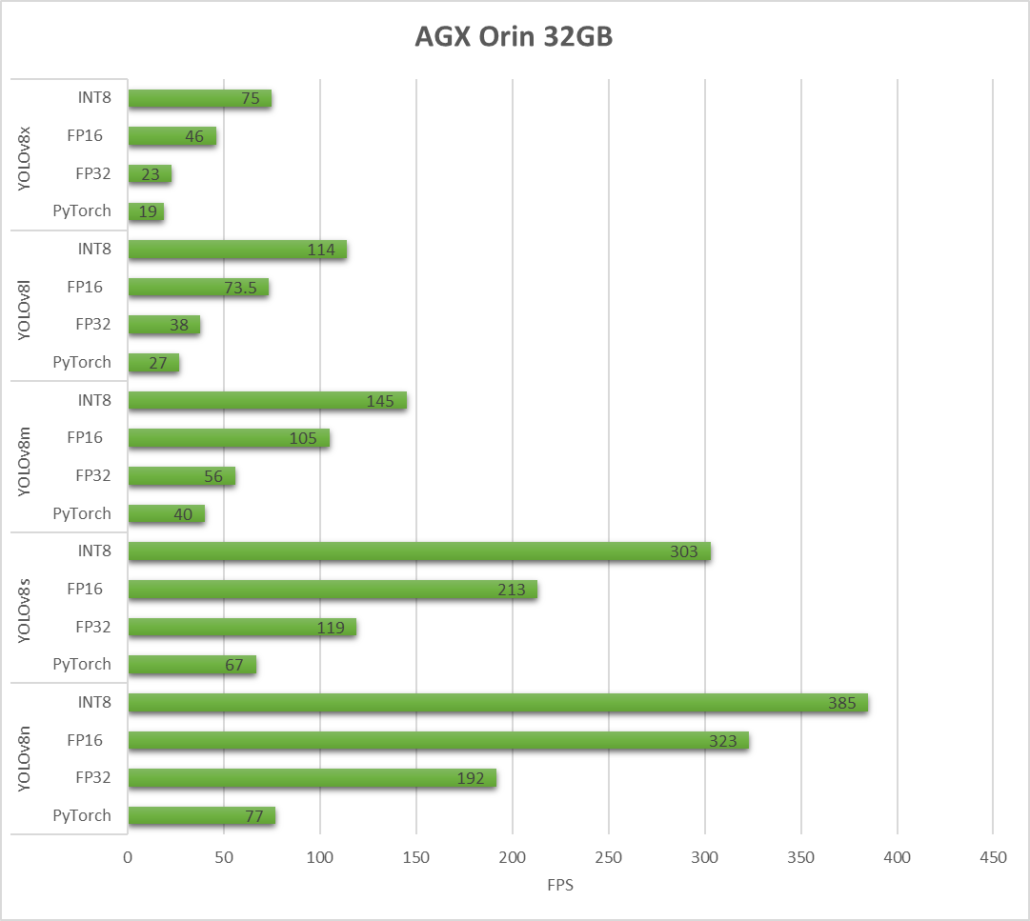
AGX Orin 32GB H01 Kit
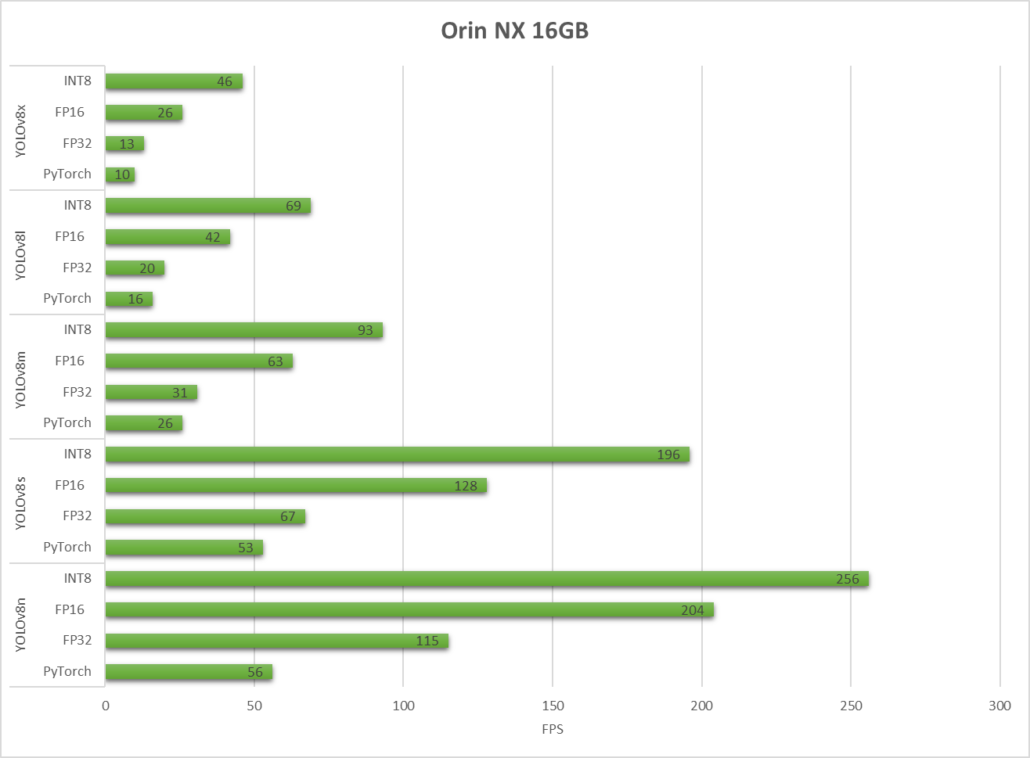
reComputer J4012 built with Orin NX 16GB
reComputer J2021 built with Xavier NX 8GB
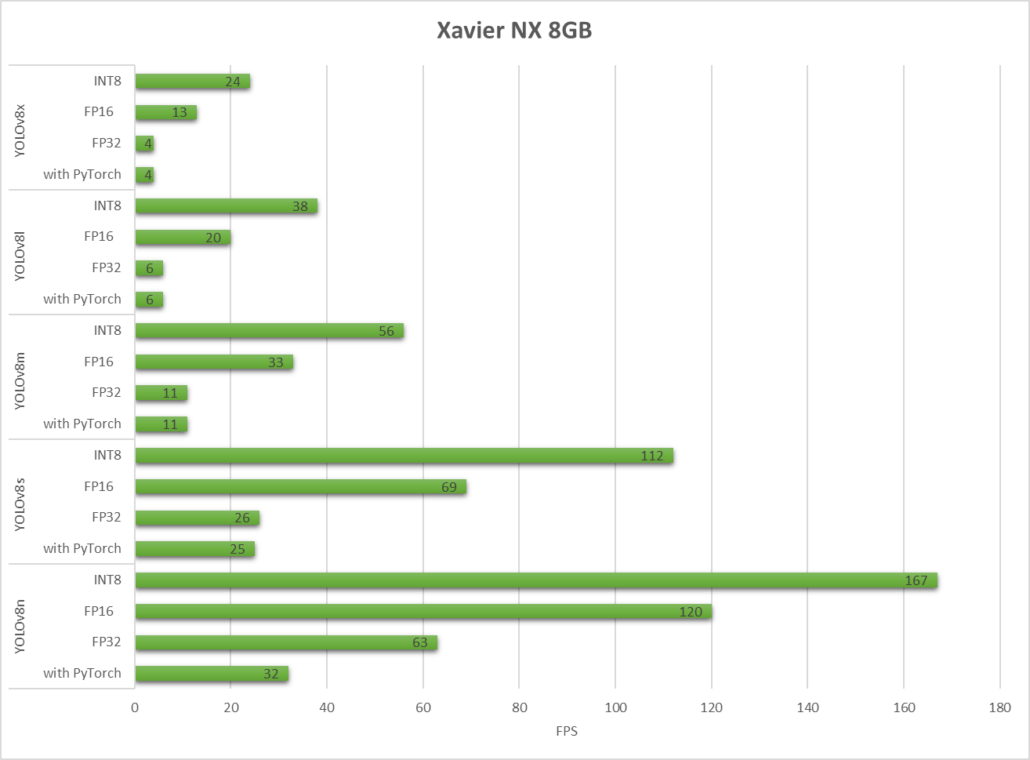
As we can see, TensorRT can give a drastic performance jump.
Next, we will look at the benchmark graphs from a different perspective where each YOLOv8 model’s performance is compared on different devices.
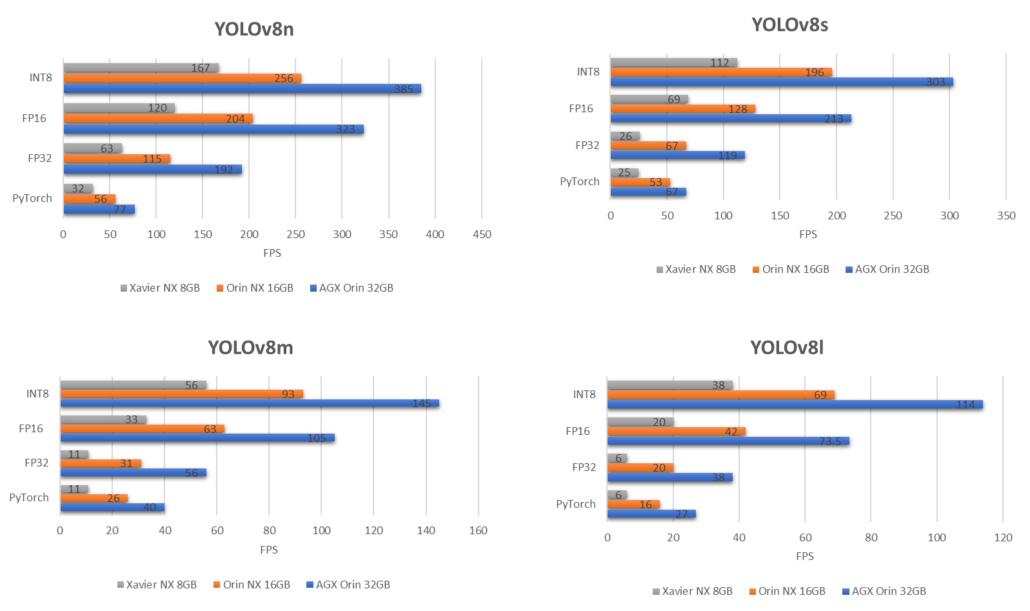
If we compare the biggest YOLOv8 model which is YOLOv8x running on the above 3 devices, this is what we get
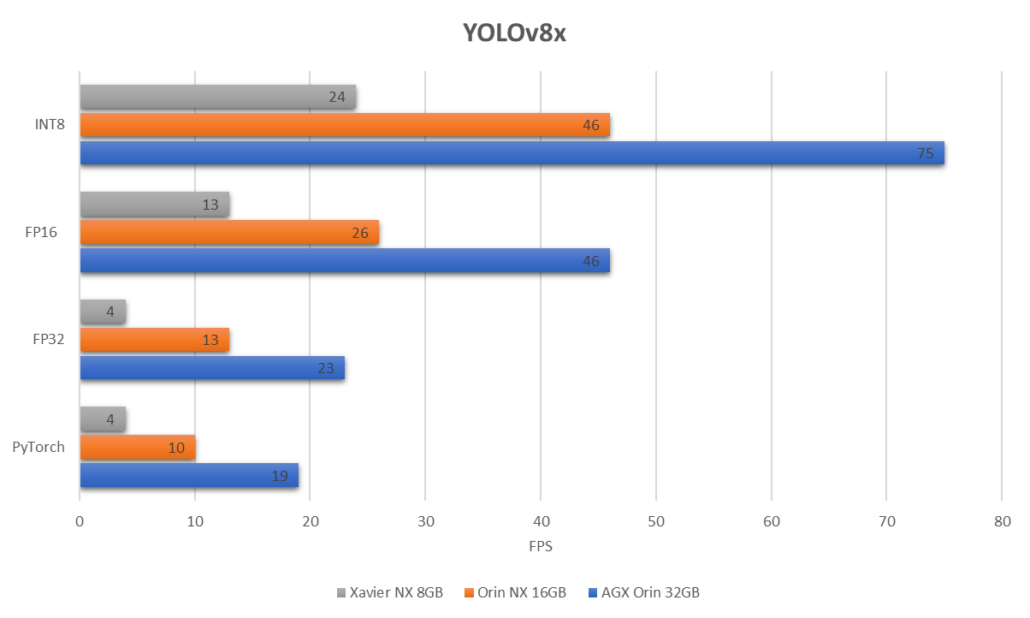
As you can see, with INT8 precision on the biggest YOLOv8x model, we can achieve an FPS of about 75 on the AGX Orin 32GB, which is very impressive for an embedded device!
Conclusion
According to all the above benchmarks, it seems that the inference performance has dramatically increased over the years on embedded devices such as the NVIDIA Jetson Orin platform and now we are almost on the way to matching server level performance with such compact devices!