Last week I had the opportunity to give a talk at UAM during their Electrical Engineering Week, an event where several professionals come to share talks about technology with students and teachers. This time the talk was a collaboration between Seeed Studio and AG Electronica, bringing together hardware expertise and local distribution to put real devices in front of the students.
It was a great space to meet people who are curious about where the field of AI/ EdgeAI is heading, and I wanted to bring them a topic that I think is becoming more and more relevant: running AI models locally instead of depending completely on the cloud.
My talk was focused on this idea: you can run capable models right where the data is generated, on hardware you can hold in your hand. To make the point concrete instead of theoretical, we prepared three live demos, each one showing a different level of compute that lets you run models locally. My goal was to make students realize that even though right now everyone is talking about huge data centers for AI inference, a lot of heavy lifting can still be done locally if you think about the system correctly.
Demo 1: TinyML on the XIAO ESP32S3 Sense
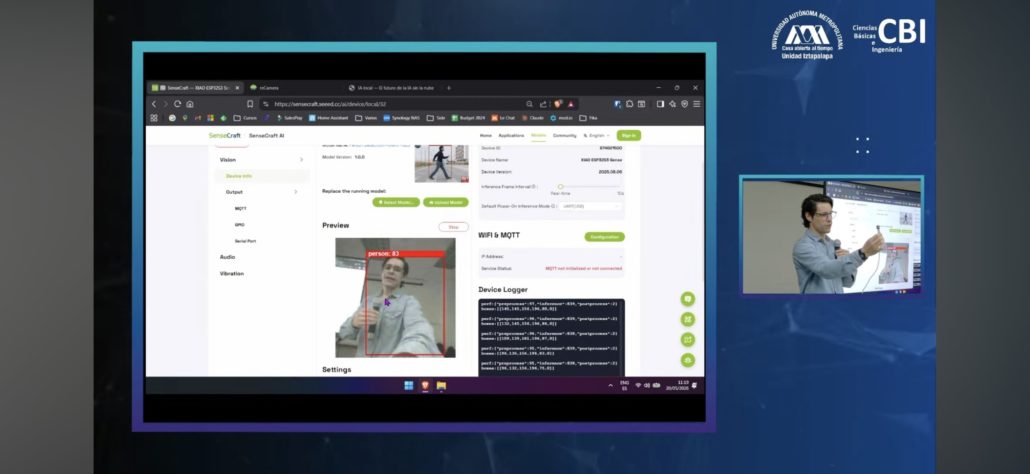
Sensecraft AI platform showing live object detection running in the Xiao Sense
We started with the smalles device in order to gain traction, the Seeed XIAO ESP32S3 Sense, using the SenseCraft AI platform. The goal here was to show that a device drawing less than 3W of power can still run something as elaborate as a real time object detection model. People are often surprised with this demo. A microcontroller that fits on a coin, sipping power, and still doing computer vision on its own. Using SenseCraft AI we could deploy a model to the device and watch it detect objects live, no cloud involved at any point. This is the entry door to local AI, and it shows that you do not need a data center to get started.
Demo 2: Higher framerate with the reCamera
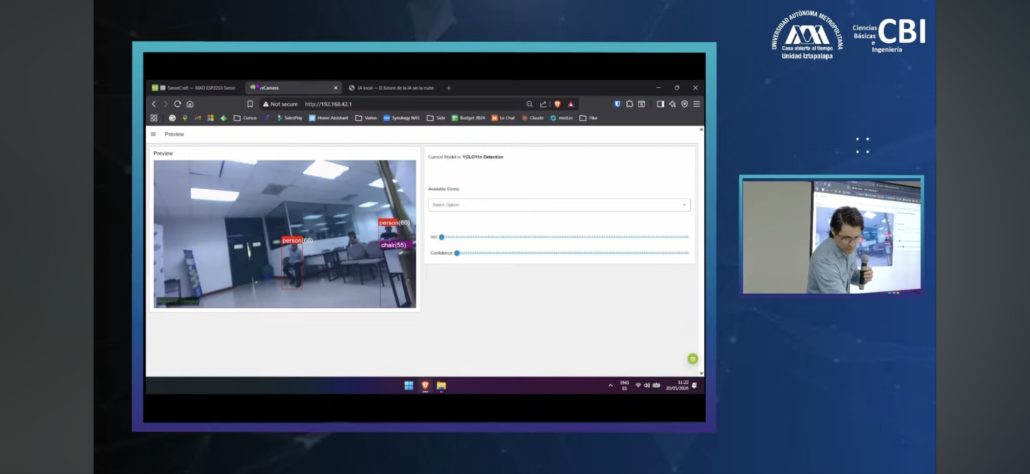
Another object detection demo, this time running on the reCamera 2002 HQ PoE, in contrast to the Xiao Sense, people saw the advantage of running inferences with accelerated hardware.
Next we did a demo with the Seeed reCamera HQ. We ran an object detection model here too, but the point was to show the difference that dedicated hardware makes. Thanks to its onboard AI processor, the reCamera handled the same kind of task with a noticeably higher fps than the XIAO.
This was a nice way to show the audience that “running locally” is not a single thing or type of model. There is a whole ladder of devices, and as you climb it you trade a bit more power and cost for more performance. The reCamera sits in that middle ground where you still have a compact, self contained camera doing all the inference on device, just faster and smoother.
Demo 3: Agentic coding on the reComputer J4012
For the top of the ladder we brought the Seeed reComputer J4012, powered by the NVIDIA Jetson Orin NX with up to 100 TOPS of AI performance. This is where things got really fun. We ran a local Qwen3 model on the device and used it for agentic coding through OpenCode.
To make it tangible, we built a small project on the spot: processing some CSV files with the model driving the work. The interesting part was watching the token generation speed. With GPU acceleration on board, the device produced tokens fast enough to feel genuinely useful for real tasks, all running locally on a box that sits on your desk. Seeing a capable coding assistant work without sending a single line of code to the cloud made the whole concept click for a lot of people.
Code being generated live during the talk. There was a wow factor when it started generating code. I mentioned it would take some time, and through that explanation the reComputer finished all of the code needed.
What students and teachers where curious about local AI
One thing that stood out to me was the kind of questions people asked. A lot of the interest centered on how local models could be implemented in remote areas, places that are low income and have limited tech infrastructure. It makes a lot of sense. If your connectivity is unreliable or expensive, a model that runs entirely on device is not just a nice feature, it can be the only practical way to bring AI to where it is needed.
Talking through these scenarios with students and teachers was one of my favorite parts of the day. It is the kind of problem where edge AI is not a luxury but a real solution.