Tips for Improving Object Detection Model Accuracy: Optimize YOLOv8 Deployment on NVIDIA Jetson!
In the realm of computer vision and artificial intelligence, developers are currently meeting a formidable challenge: the obvious gap between the object detection accuracy demonstrated by cutting-edge models and the actual results achieved in practical applications. The disparity arises from a multitude of technical challenges – First and foremost, these models often rely on vast datasets and compute resources that are challenging to replicate in real-world settings. Moreover, issues such as domain adaptation, fine-tuning intricacies, and the inherent bias in training data further complicate the quest for high accuracy.
In this journey, we will explore a range of methods and strategies to tackle this problem head-on, offering insights into how developers can enhance their object detection systems to meet the high standards set by these advanced models.
Why the actual detection accuracy is not so promising?
As we mentioned before, the shortage in achieving promising object detection accuracy in real scenarios can be attributed to several intricacies arising from the disparity between the original training and testing datasets, such as the widely used COCO dataset, and the real-world deployment data or images.
- Status category based on one kind of object: (e.g.: fresh apple vs. rotten apple) One primary source of this discrepancy is the inherent variation in object categories. While the COCO dataset encompasses an extensive array of object categories, real-world scenarios introduce unseen or less-represented categories, thereby challenging the model’s ability to generalize accurately.
- Variations in object orientations and viewing angles: encountered in deployment scenarios can significantly differ from the controlled settings of the training data, leading to unsatisfied performance.
- Lighting conditions: variations in illumination levels and environments pose a significant challenge for models initially trained on well-lit, standardized images.
As a result, these discrepancies collectively pose a technical barrier to achieving the desired detection accuracy, requiring innovative solutions and techniques to bridge the gap between training data and real-world deployment scenarios.
Existing method we can optimize
1. Extending the Dataset for Enriching Generalization:
One of the most efficient and cost-effective strategies to boost object detection accuracy is by extending the dataset. This entails collecting additional data specifically tailored to the deploying scenes. By doing so, we not only increase the volume of data available for training but also ensure that our model encounters the unique challenges posed by real-world scenarios. Handling missing data and improving labeling precision are essential aspects of this process.
2. Feature Extraction for Enhanced Understanding:
By extracting more information from existing data and creating new features, we enhance the model’s ability to interpret and understand the nuances of the training data. Addressing issues like variable skewness and outliers through careful feature engineering can mitigate the impact of these challenges on model performance, ultimately leading to more robust and accurate object detection.
3. Leveraging Multiple Algorithms for Better Performance:
Combining multiple algorithms can unlock substantial improvements in object detection accuracy. A notable example is the introduction of YOLO-ReT, a groundbreaking module designed for multi-scale feature interaction. This novel approach exploits previously untapped combinatorial connections between various feature scales in state-of-the-art methods. YOLO-ReT, when paired with a MobileNetV2×0.75 backbone, not only achieves remarkable accuracy, with 68.75 mAP on Pascal VOC and 34.91 mAP on COCO but also delivers superior speed, outpacing its peers by 3.05 mAP and 0.91 mAP, all while running in real-time on platforms like NVIDIA Jetson Nano. This innovative approach represents a paradigm shift in object detection, offering both precision and efficiency.
Next step – getting exercise on training the model with your own dataset
Follow our application engineer Lakshantha’s wiki guidance to figure out how to better annotate your dataset through Roboflow, and then how to train your model with your own dataset using YOLOv8:
1. Use Roboflow to bring your model into the workspace, then copy the private Roboflow API
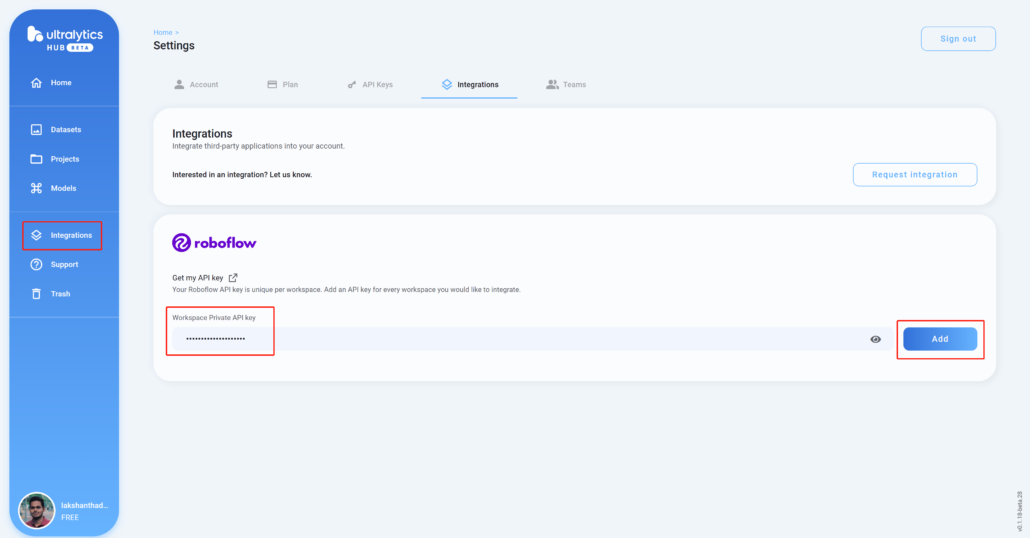
2. Add the Roboflow workspace into Ultralytics HUB
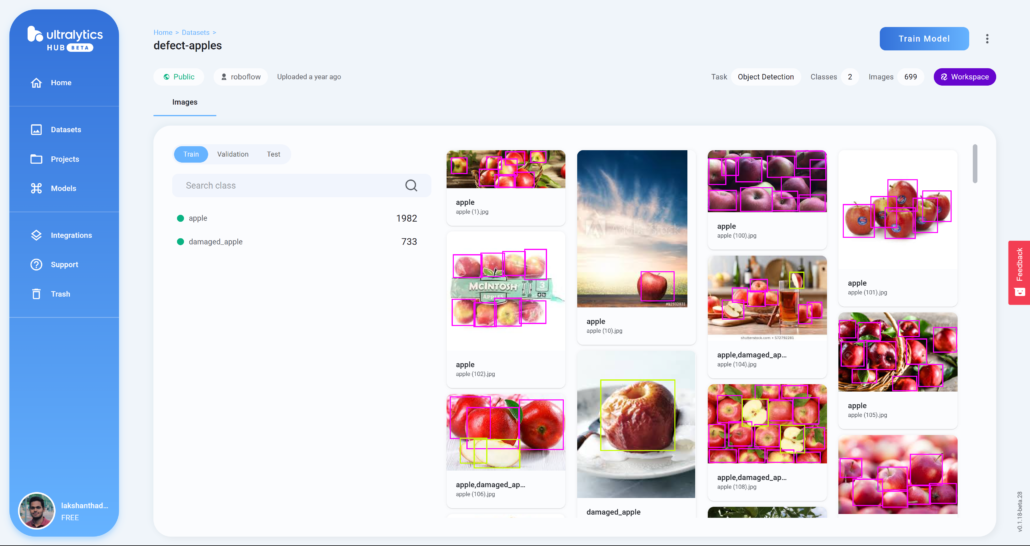
3. Train the model with YOLOv8s as the model architecture, using the dataset that you can navigate through your Roboflow workspace
4. Connect Google Colab notebook with Ultralytics HUB to easily start the training process and also view the training progress in real time
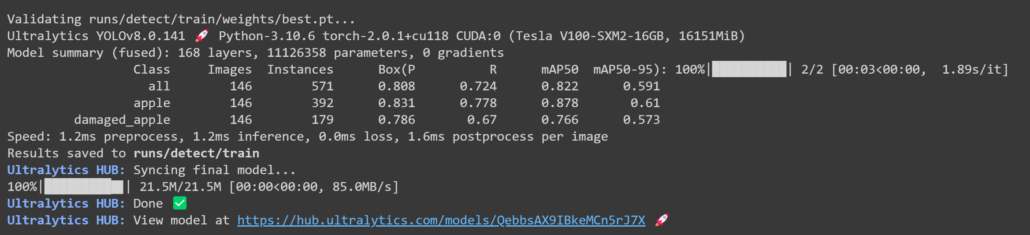
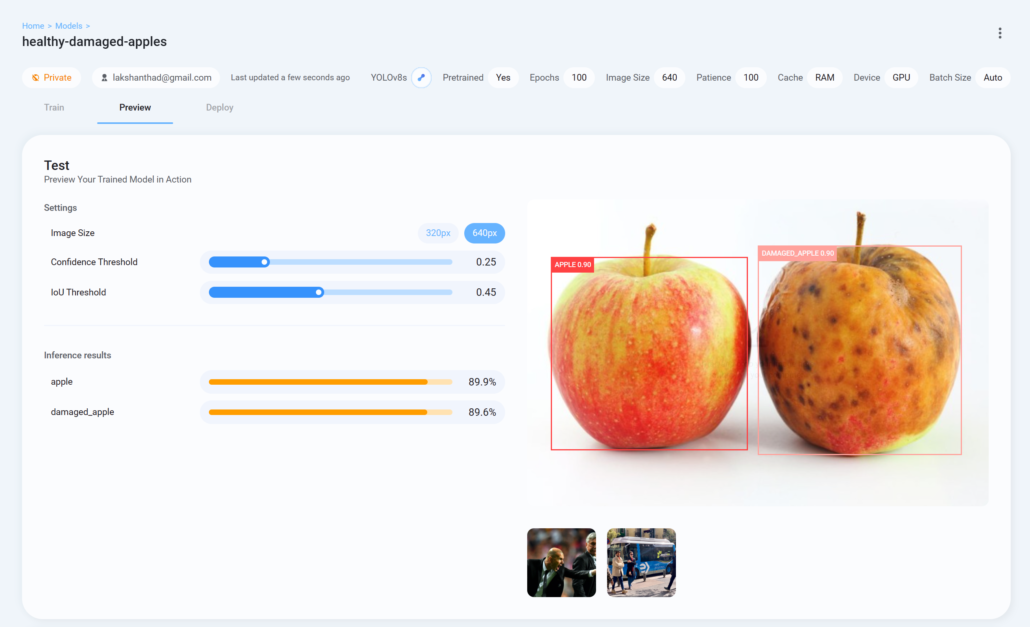
5. Upload a test image for model performance checking on the Ultralytics HUB Preview tab, and finally download the trained model in the format you prefer to inference with YOLOv8
Seeed NVIDIA Jetson Ecosystem
Seeed is an Elite partner for edge AI in the NVIDIA Partner Network. Explore more carrier boards, full system devices, customization services, use cases, and developer tools on Seeed’s NVIDIA Jetson ecosystem page.
Join the forefront of AI innovation with us! Harness the power of cutting-edge hardware and technology to revolutionize the deployment of machine learning in the real world across industries. Be a part of our mission to provide developers and enterprises with the best ML solutions available. Check out our successful case study catalog to discover more edge AI possibilities!
Take the first step and send us an email at [email protected] to become a part of this exciting journey!
Download our latest Jetson Catalog to find one option that suits you well. If you can’t find the off-the-shelf Jetson hardware solution for your needs, please check out our customization services, and submit a new product inquiry to us at [email protected] for evaluation.