Why Indoor Safety Systems That Work in One Building Fail at Campus Scale
Most indoor safety systems work perfectly in a single building. The environment is controlled, and the setup is simple. But when you expand to a full campus, the rules change.
Scaling isn’t just about adding more devices; it’s about managing new trade-offs in coverage, accuracy, and reliability. The assumptions that made your pilot a success, like predictable layouts and easy device management, no longer hold true in a complex, multi-building environment.
To avoid a system that fails when it’s needed most, you need to rethink your approach before you grow.
Why Scaling Indoor Safety Systems Is a Different Problem
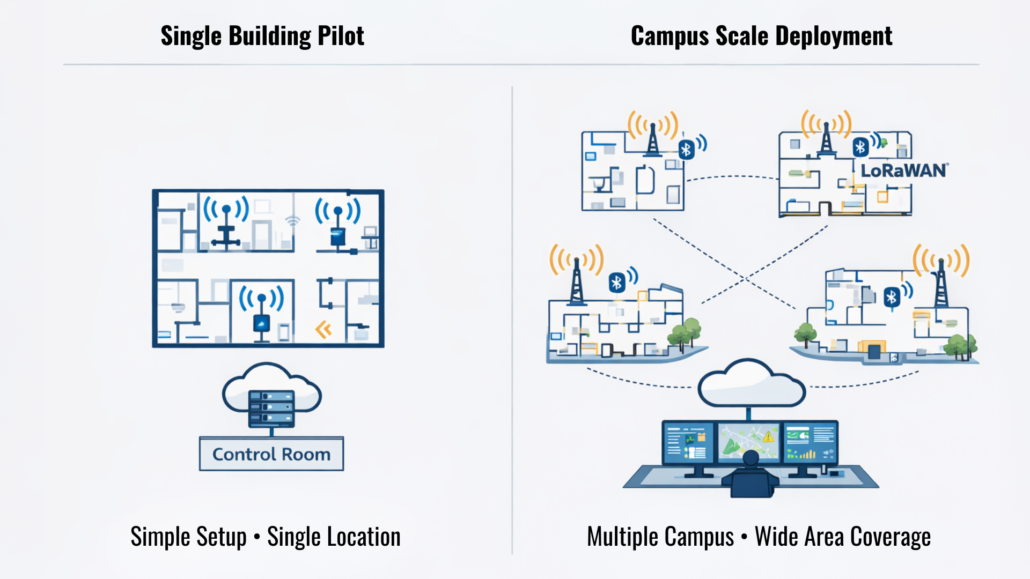
Indoor safety systems often work perfectly in a single building. The setup is simple, and everything performs exactly as expected. But when you expand across an entire campus, the system starts to behave differently.
The issue isn’t that the technology stops working. Instead, scaling introduces unavoidable trade-offs between coverage, accuracy, and reliability. Even if you use the same network, the way the system operates and the results you get will change as the environment gets more complex.
Why Single-Building Pilot Assumptions Don’t Hold at Campus Scale
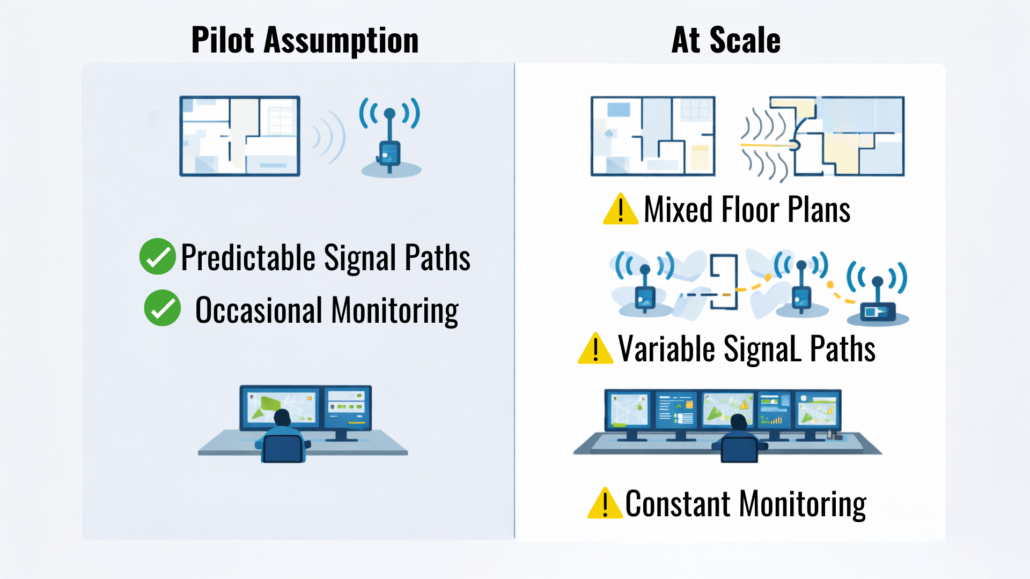
Single-building pilots are usually conducted in relatively controlled environments. To move quickly, teams often rely on assumptions that simplify deployment and validation.
Common assumptions include:
- Predictable Layours: Assuming every building behaves similarly, when in reality, different designs and occupancy levels change how signals travel.
- Consistent Signals: Assuming signal conditions remain the same throughout the entire system, though signal paths become highly variable at scale.
- Simple Workflows: Assuming alert and response workflows are easy to manage, ignoring the need for constant monitoring as device counts grow.
These assumptions are reasonable at pilot scale because they reduce complexity and make early validation easier. In a single building, teams can rely on familiar layouts, predictable usage patterns, and limited device counts to confirm that everything behave as expected.
However, once deployments expand across multiple buildings, these guarantees disappear. Differences in building design, occupancy, and daily operations introduce new variables. This is usually when the system begins to behave differently than it did during your pilot.
How Scale Affects Reliability, Operations, and Performance
As indoor safety systems expand, the most noticeable shift is in how reliability is evaluated. During pilots, occasional delays or minor inconsistencies may be acceptable. At campus scale, these small issues become critical safety risks, teams often revisit architectural approaches that balance indoor location accuracy with reliable, long-range communication, especially when consistent alert delivery becomes more important than perfect precision.
It is important to understand that the challenge at scale is usually not network fragmentation. Even when you deploy multiple LoRaWAN gateways across different buildings, they are typically connected to the same LoRaWAN Network Server (LNS) and operate as one single system.
The real difficulty lies in maintaining consistent behavior and performance as that single network grows.
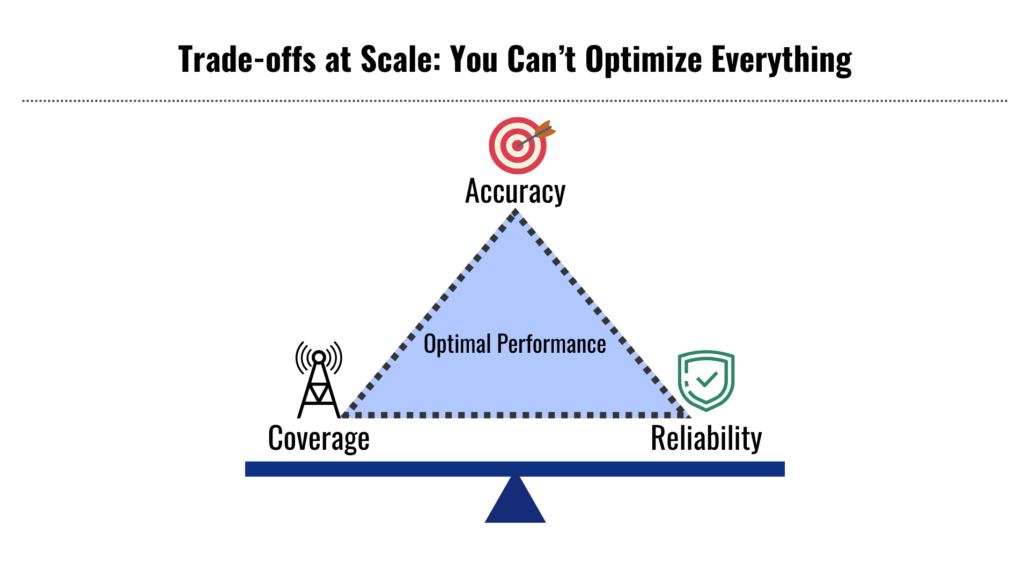
Operational complexity increases much faster than many teams expect. Higher device counts, wider coverage areas, and more diverse environments introduce ongoing management demands, from monitoring system health to handling maintenance and troubleshooting.
Simply adding more devices does not account for how system load, reliability requirements, and operational complexity change as deployments grow. At scale, teams often need to rethink how devices are distributed across spaces and how network coverage is planned.
As scope grows, teams place greater emphasis on predictable system behaviour over time, especially during peak usage or less controlled scenarios. This is often when gaps between pilot performance and real-world operation begin to surface.
Together, these shifts show that scaling is not just about extending coverage, but about ensuring the system can operate reliably and sustainably as complexity increases.
How Teams Usually Adjust Their Approach
Teams that scale successfully don’t just copy-paste their pilot setup; they fundamentally adjust their strategy. As the scope grows, the priority shifts from basic testing to ensuring consistent behavior across every building and operating condition.
In practice, this involves three key shifts:
Architectural Resilience: Prioritizing guaranteed alert delivery over pinpoint precision to ensure the system works when it matters most.
Workflow Optimization: Stripping away complex response protocols that cannot handle high device counts.
Phased Validation: Using staged rollouts to test assumptions and catch issues before they become campus-wide failures
By treating scale as a progresive process instead of a one-time expansion, teams can better manage complexity and maintain system reliability as requirements evolve.
Don‘t Wait for an Emergency to Test Your Scale
What works in a single building rarely translates directly to a campus-wide deployment. If you are moving beyond the pilot phase, your biggest risk is not the hardware itself, but the hidden trade-offs in coverage and reliability that only surface at scale.
Don’t find out your system fails when it is needed most. Talking through your deployment trade-offs and expansion considerations early can prevent costly rework and ensure your safety system is built to perform when it counts.
Connect with our experts to discuss your current setup and understand how different design choices will affect your system’s performance at scale.