Deploy CLIP Zero-shot Classification on Jetson Orin – Fast Locate and Categorize Data without Training
The traditional method of image classification is quite time and resource-consuming. It requires more than millions of labeled images as a huge dataset preparation, which is highly consistent with your targeted object and can be used to train the supervised classification model for the next step.
However, supervised training can not always deliver good performance in general usage. Suppose you will test the model with another image in a different domain or include a similar object within an unfamiliar application scenario. In that case, it may identify the object as the unexpected class. That’s where CLIP(Contrastive Language–Image Pretraining) unleashes the power of multimodal learning at a fast speed.
Understand of CLIP
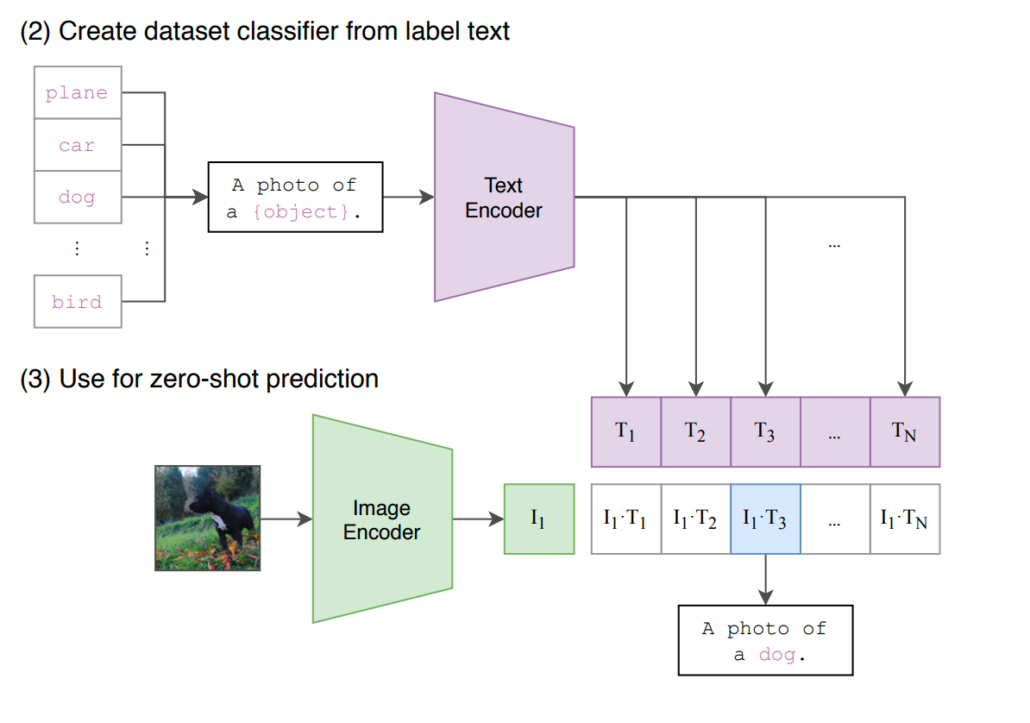
So, what is CLIP? CLIP, which stands for Contrastive Language-Image Pretraining, is a computer vision model developed by OpenAI. It excels in understanding the relationship between images and their corresponding textual descriptions, built on a large body of work on zero-shot transfer, natural language supervision, and multimodal learning.
Basic Architecture
Contrastive learning in pre-training
CLIP utilizes the Vision Transformer (ViT) architecture to process images, enabling the model to capture global relationships among image features. Meanwhile, for text processing, CLIP employs a transformer-based architecture, tokenizing and processing text through transformer layers to understand semantic relationships within textual descriptions without predicting texts word for word.
The model is trained using pairs of images and text, aiming to minimize the distance between positive pairs (comprising an image and its corresponding description) and maximize the distance between negative pairs (comprising an image and a randomly chosen description). This contrastive learning objective encourages the model to learn a meaningful representation where related content is close and unrelated content is separated.
Fine-tune for downstream tasks
After pre-training, CLIP can be fine-tuned on specific downstream tasks with task-specific datasets. You can easily tailor CLIP’s behavior to specific tasks and domains with prompt engineering. By utilizing a prompt template or even prompt ensembling, which uses multiple prompt templates with more contextual modifications added to match possible situations, the accuracy of similarity matching can be improved.
Why is CLIP important as a foundation model?
Unlike traditional models that require extensive labeled datasets for training, CLIP leverages a unique approach—pretraining on a vast dataset containing image-text pairs from the Internet, enabling it to perform a wide array of tasks without the need for task-specific training data. The model’s ability to connect vision and language makes it adept at tasks such as image classification and even generating textual descriptions for images.
You only need to define the possible prompts or descriptions the objects of the scene belong to, then CLIP will help you predict the most probable class for the given image or video based on its extensive pertaining.
In this guide, we are going to show application insights and running performance using CLIP on the Edge. Basically, CLIP can be deployed for:
Advertisement search engine: classify video advertisement’s category, featured by shooting scenarios or specific main objects.
Content Moderation: identify and flag potentially inappropriate or harmful content in images and videos.
SNS video recommendation: classify the video content and deliver recommendations based on audiences’ interest or viewing history.
Pinpoint important periods of the event in a long video: improve the efficiency for police to find the crime evidence on time.
Automation of the process in QSR: check what ingredients and sauces should be put in the delivered pizza, and provide a production list according to the visual comparison
Interior home design reference: help you discover visually similar interior design ideas based on your provided preferred decorating style images.
We’ll see that the industry and application direction of CLIP is unlimited! So now, let’s dive deep into how to deploy CLIP at the edge to solve your image classification and other project tasks.
Deploy CLIP on the Site for Classification
Here are some of the interesting demos that we have deployed CLIP models on the reComputer J4012 based on NVIDIA Jetson Orin NX 16GB using the Roboflow Inference Server. You can take reference of Roboflow’s blog for step-by-step guidance, however, just need to change the first Inference server installation part to the following code as adding TensorRT support, since we are using GPU:
```sh
git clone https://github.com/roboflow/inference
cd inference
sed -i '/ENV OPENBLAS_CORETYPE=ARMV8/a ENV ONNXRUNTIME_EXECUTION_PROVIDERS=TensorrtExecutionProvider' docker/dockerfiles/Dockerfile.onnx.jetson.5.1.1
docker build \
-f docker/dockerfiles/Dockerfile.onnx.jetson.5.1.1 \
-t roboflow/roboflow-inference-server-jetson-5.1.1:seeed1 .
```
- Run the container
```sh
docker run --privileged --net=host --runtime=nvidia roboflow/roboflow-inference-server-jetson-5.1.1:seeed1
```Image-Prompt pair
Now you can easily classify images into different categories without training your model in advance.
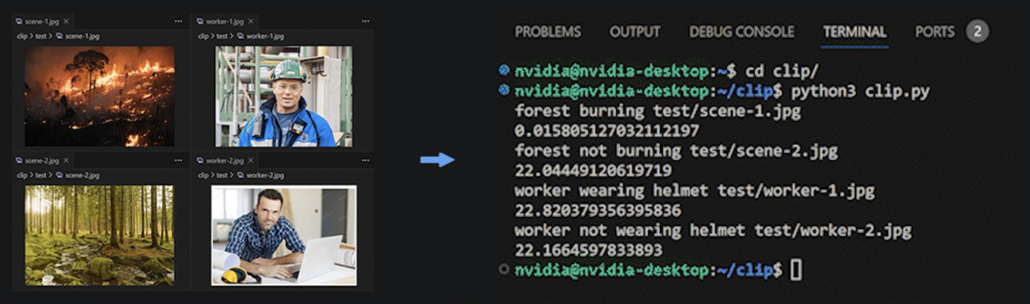
Start the Roboflow Inference Server Docker container on the Jetson Edge device, define the Roboflow API key, and run a demo script to start classifying different images based on the prompts you define. We have used Jetson Orin NX 16GB for this demo and it was able to achieve around 22 FPS performance with TensorRT FP16 precision!
All you need to consider is prompt engineering – to find a more accurate or proper prompt to describe the scene of the image clearly for better classification performance, which means you need to tell CLIP what it should recognize in the image. This whole process of finding the correct prompt could be a long-term trial and error.
If you also want to show the inferencing speed as our demo performed, feel free to add this part easily in the result out print part:
for file in sorted(os.listdir(IMAGE_DIR)):
image = f"{IMAGE_DIR}/{file}"
predictions = classify_image(image)
print(get_highest_prediction(predictions["similarity"]), image)
print(1/(predictions['time']))
Video theme classification
Understanding a video scenario involves breaking down a video into individual frames, applying CLIP independently to each frame for image understanding, and then integrating temporal information across frames.
By fusing features extracted from both individual frames and their temporal context, the model creates a representation that captures the overall content and context of the video. The fused features are then used for scenario classification, predicting the depicted activity or scenario. Fine-tuning a dataset containing video frames and scenario labels may be necessary to adapt CLIP to the specific requirements of the video task. The performance of the model is evaluated using standard metrics, and adjustments are made as needed for optimal results.
In this demo, we use CLIP to identify the video as a scene containing a package. We can classify the scenario type, at what timestamps the package first appears, and how long it’s visible on the scene. It could be a perfect experiment for preventing package delivery from being stolen. Simply follow Roboflow’s blog to classify the video step-by-step, also remember to import the supervision library at the beginning since we are going to use supervision to split up our video into frames.
import supervision as sv
Seeed: NVIDIA Jetson Ecosystem Partner
Seeed is an Elite partner for edge AI in the NVIDIA Partner Network. Explore more carrier boards, full system devices, customization services, use cases, and developer tools on Seeed’s NVIDIA Jetson ecosystem page.
Join the forefront of AI innovation with us! Harness the power of cutting-edge hardware and technology to revolutionize the deployment of machine learning in the real world across industries. Be a part of our mission to provide developers and enterprises with the best ML solutions available. Check out our successful case study catalog to discover more edge AI possibilities!
Take the first step and send us an email at [email protected] to become a part of this exciting journey!
Download our latest Jetson Catalog to find one option that suits you well. If you can’t find the off-the-shelf Jetson hardware solution for your needs, please check out our customization services, and submit a new product inquiry to us at [email protected] for evaluation.