From Robot’s Ears to Intelligence: How Reachy Mini Understands the World with a Microphone Array
How do Robots Really “Hear Direction”?

Since the launch of Reachy Mini, we’ve been consistently hearing discussions in the community around a simple but powerful idea: What if robots had “ears” like humans?
That means not just microphones for recording sound, but actual spatial hearing, the ability to tell where a sound comes from and react accordingly, without relying on vision.
This question reflects a deeper shift in user expectations. People are no longer asking: “Can the robot hear?”
They are asking: “Can the robot understand space through sound?”
Reachy Mini’s Hearing System: More Than Just Microphones

Reachy Mini is not just equipped with microphones, it is designed with spatial audio sensing in mind.
\At the top of its head, Reachy Mini integrates a customized reSpeaker 4-microphone linear array based on reSpeaker XMOS XVF3800.
*To learn more about the microphone array used in Reachy Mini, check out this blog.
*To learn more about how to use the reSpeaker inside Reachy Mini for DoA detection, please read here.)
This setup enables:
- Enhanced audio capture within a forward-facing 180° field
- Improved overall audio pickup quality
- Better understanding of voice commands and more responsive interactions
This is not a recording device, it is a spatial perception audio sensor.
What Is a Microphone Array?
A microphone array consists of multiple microphones arranged in a specific geometry. Common configurations on the market include 2-, 4-, 6-, and 8-mic setups, with physical layouts such as linear and circular arrays.
Because of the number of microphones and their spatial arrangement, a microphone array does more than just capture high-quality sound. It enables AI-driven acoustic processing, such as beamforming, automatic gain control (AGC), acoustic echo cancellation (AEC), and dynamic noise suppression.
Most linear arrays are optimized for directional pickup, typically covering a forward-facing 180° field. In contrast, circular arrays provide full 360° coverage and enhance spatial awareness, enabling Direction of Arrival (DoA) detection.
At a high level, microphone arrays analyze spatial differences between microphones, such as:
- Which microphone receives the sound first
- Which microphone receives a stronger signal
- How waveforms align across channels
These differences allow the system to reconstruct where a sound originates in space.
Compared to a single microphone, arrays enable:
- Directional awareness
- Better noise robustness
- Far-field voice capture
- Multi-source separation
In short, a microphone array transforms audio from raw sound into spatial information.
How Robots “Hear Direction”: Core Technologies
1. Key Concepts: What They Mean and How They Work
DoA (Direction of Arrival)
DoA estimates the direction (angle) from which a sound arrives. It is the final output of spatial audio processing, used to determine where a speaker or sound source is located.
How it works:
DoA is not measured directly. Instead, it is computed by combining multiple acoustic cues captured across microphones.
To estimate these cues in practice, several well-established algorithms are commonly used:
- GCC-PHAT: the most widely adopted method for estimating time delay between microphones
- SRP-PHAT: more computationally intensive, but better suited for multi-source environments
- MUSIC: a high-resolution approach that enables precise localization, at the cost of higher complexity
The system compares how sound propagates across multiple microphones, and from these spatial differences, it infers the direction of the sound source.
ITD (Interaural Time Difference)
ITD is one of the core mechanisms behind DoA. It refers to the tiny time difference between when a sound reaches different microphones. In humans, this is exactly how our ears work — sound arriving from one side reaches one ear slightly earlier than the other.
How it works:
- Assume two microphones are placed at a distance d
- If sound comes from the left → the left microphone receives it first
- The system measures the time delay (Δt) between the two signals
- Using the speed of sound (~343 m/s), this delay can be converted into an angle
At its core, the principle is simple:
Time difference = Distance difference / Speed of sound
In practice, systems use techniques like cross-correlation to precisely estimate this delay between signals.
This is the primary cue for low-frequency localization and closely mimics human hearing.
ILD (Interaural Level Difference)
ILD refers to the difference in sound intensity (or energy) captured by different microphones.
How it works:
- The microphone closer to the source captures a stronger signal
- The system compares signal energy across channels
- Greater level difference → sound is more off-center
When a sound arrives from one direction:
- The microphone closer to the source captures a stronger signal
- The farther microphone receives a weaker signal due to attenuation and physical obstruction
In human hearing, this is influenced by the “head shadow” effect, where the head blocks part of the sound energy.
ILD is especially effective for high-frequency sounds, where shadowing effects are stronger.
How it’s implemented in microphone arrays:
- Capture audio simultaneously across multiple microphones
- Calculate signal energy (e.g., RMS or power) for each channel
- Compare the intensity differences
- Infer the direction based on which side is stronger
Phase Difference
Phase difference captures how aligned the waveforms are across microphones at a given frequency.
How it works:
- Instead of measuring coarse time delay, phase analyzes waveform alignment
- Even small shifts in phase can indicate direction
- Enables fine-grained, high-resolution localization
This is often used in advanced algorithms to refine DoA estimation.
2. How These Concepts Work Together
These are not independent features, together they form a hierarchy:
- ITD, ILD, and Phase Difference → provide raw spatial cues
- These cues are fused → to estimate DoA
In other words:
Time difference + Level difference + Phase difference → Direction
Each cue has strengths in different conditions:
- ITD → robust for low frequencies
- ILD → effective for high frequencies
- Phase → improves precision
By combining them, systems achieve stable and accurate localization.
3. From Detection to Tracking
Traditional systems:
- Detect sound direction once
- Trigger a response
Modern systems:
- Continuously monitor these cues over time
- Track how the sound source moves
Key ideas:
- Temporal cadence: how often direction is updated
- Tracking stability: avoiding jitter in direction estimates
- Phase evolution: how phase changes over time to reflect motion
This shifts the problem from “Where is the sound?” to “How is the sound moving?”
Instead of simply reacting to isolated sound events, robots are beginning to build a continuous understanding of the surrounding acoustic environment.
4. From Microphone Arrays to Spatial Awareness
All of the above relies on one foundation: microphone arrays.
A single microphone can only capture sound intensity. A microphone array, however, enables:
- Measuring time differences (ITD)
- Measuring level differences (ILD)
- Analyzing phase relationships
These capabilities allow the system to compute DoA and track sound sources in space.
5. What This Means for Robots
By leveraging these technologies, robots gain a new layer of perception:
- Identify where a person is speaking from
- Turn toward the speaker
- Follow moving voices
- Distinguish between multiple sound sources
Microphone arrays turn sound into spatial information, enabling robots to move from passive listening to active perception.
Different types of robots also require different forms of spatial hearing and voice interaction.
For many robots, the expected direction of incoming sound is relatively predictable. Desktop robots, for example, often receive voice commands from users standing or sitting nearby, typically within a forward-facing or upper-front acoustic field. Interactive robots used in smart retail or customer service scenarios usually rely on face-to-face communication, where directional pickup and speech clarity in front of the robot become especially important.
Humanoid robots, however, require a much stronger sense of spatial awareness. This often means:
- Wider pickup coverage, such as full 360° sensing
- Longer-distance voice capture
- More stable tracking of moving speakers in dynamic environments
Some advanced designs even place separate microphone arrays at the robot’s left and right “ears.” By combining spatial cues from both sides, the system can achieve a listening experience much closer to the human auditory system, enabling more natural sound localization and interaction.
Beyond Localization: Advanced Audio Capabilities
With microphone arrays like reSpeaker, robots can go beyond direction detection.
Speaker Tracking
Follow a person as they move and speak.
Beamforming
Focus on a specific direction while suppressing unwanted sounds from others.
Acoustic Echo Cancellation (AEC)
Remove the robot’s own voice from the microphone input.
Noise Suppression (NS)
Improve speech clarity in real-world environments — and, most importantly, suppress the internal noise generated by the robot itself.
These capabilities help transform raw audio into actionable intelligence.
Why This Matters for Robotics
1. Reduced Dependence on Vision
Audio perception works even when:
- The environment is dark
- Objects are partially occluded
- Vision systems become computationally expensive
Compared to video pipelines, audio processing can often achieve lower latency and lower compute cost.
2. More Natural Interaction
Humans naturally expect intelligent systems to react toward whoever is speaking.
Spatial hearing allows robots to:
- Turn toward the active speaker
- Maintain conversational awareness
- Create interactions that feel significantly more natural
3. Multimodal Intelligence (Audio + Vision)
Audio can guide vision.
Instead of continuously analyzing the entire visual scene, robots can first use sound to determine where attention should go:
Sound → directs camera attention
This creates faster and more efficient perception pipelines, especially in embodied AI systems where compute resources and response time matter.
A New Direction: From Localization to Sound Field Understanding
The discussion around robot hearing is also moving beyond simple direction estimation.
Instead of: delay → direction
Future systems increasingly focus on:
- Phase → orientation
- Amplitude → confidence
- Temporal patterns → stability
This leads toward a broader concept:
Sound Field Modeling
Understanding sound not as isolated events, but as a continuous spatial-temporal structure evolving over time.
Rather than simply detecting “where a sound is,” robots begin maintaining a stable acoustic understanding of the environment itself.
This is where robotics audio starts becoming part of a perception system — not just a sensor stack.
The Role of reSpeaker
The reSpeaker microphone array provides:
- Powerful far-field voice capture
- Built-in acoustic algorithms (DoA, AEC, beamforming)
- Real-time audio processing capabilities
In Reachy Mini, reSpeaker acts as:
- The hearing interface
- The foundation for spatial audio perception
A simple way to think about it:
reSpeaker = the robot’s “ears” + a layer of pre-processing intelligence
The microphone array used in Reachy Mini is based on the reSpeaker XMOS XVF3800. Building on this foundation, we have also introduced a newer microphone array solution designed specifically for embodied AI applications such as robotics and smart signage: reSpeaker Flex.
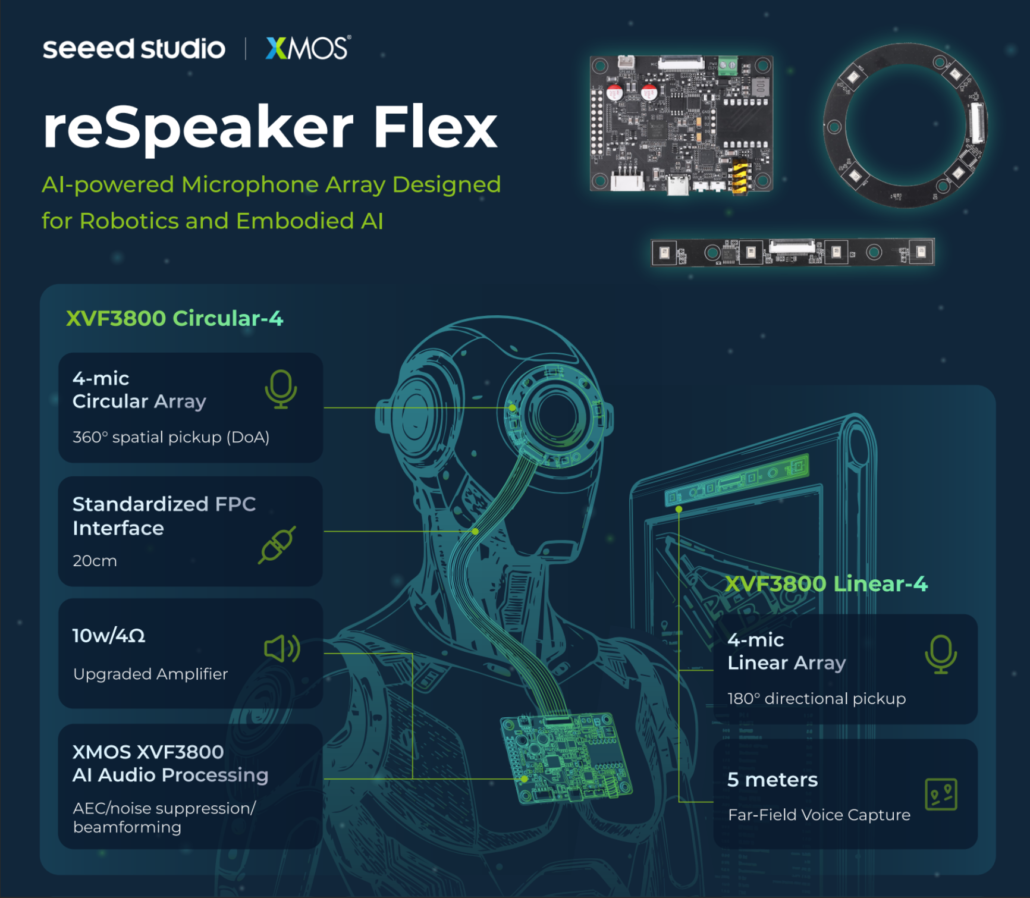
Compared to traditional integrated microphone arrays, reSpeaker Flex adopts a split-design architecture that separates the microphone array board from the processing board, making integration significantly easier in space-constrained robotic systems. It is optimized for scenarios requiring directional voice interaction, spatial audio perception, and low-latency edge AI audio processing.
reSpeaker Flex also provides:
- Flexible hardware integration for robots and embedded AI devices
- Enhanced far-field voice capture and real-time acoustic processing
- Support for advanced audio algorithms such as DoA, AEC, beamforming, and noise suppression
- Open and developer-friendly integration with platforms like ROS2, edge AI systems, and custom voice pipelines
Conclusion: Robots Are Learning to “Hear the World”
We are moving from:
Recording → Localization → Tracking → Understanding
The next generation of robots will not just see the world.
They will:
- Hear where things are
- Understand what matters
- Respond naturally in real time
And it all starts with something as simple — and as powerful — as giving robots the ability to listen like we do.